What is the purpose of optimization algorithms?
Lecture 5 – Optimization Algorithms in Deep Learning: SGD, Momentum, RMSProp & Adam Explained
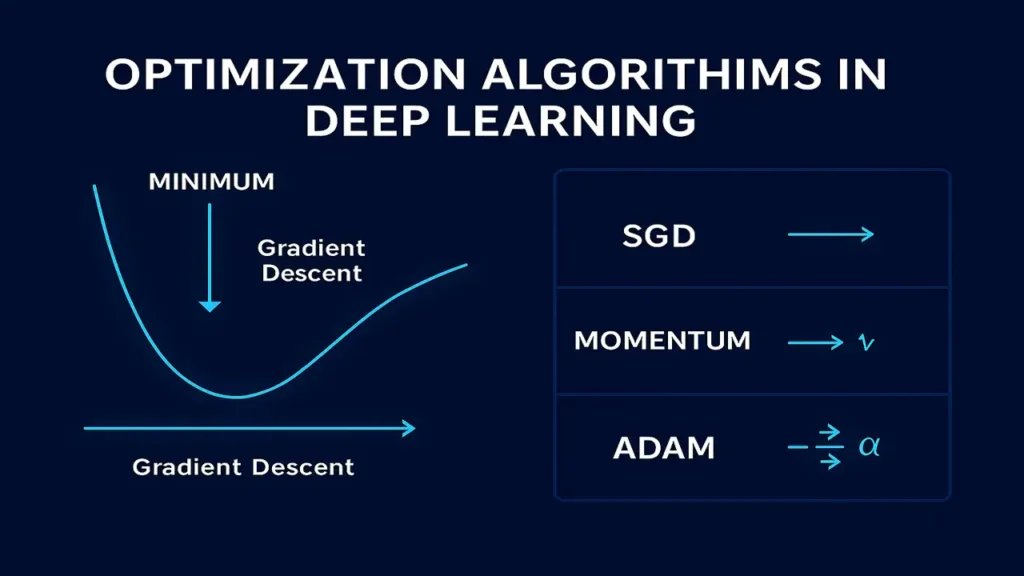
Introduction
Training a deep learning model is not just about defining layers and loss functions the real magic happens in how optimization algorithms update the model’s weights and guide learning.
This weight-updating process is performed by optimization algorithms, which determine:
- How fast the model learns
- Whether training converges
- Whether gradients vanish or explode
- Whether the model reaches a good minimum
- How stable and smooth the training curve is
Without effective optimization algorithms, even the most powerful neural networks fail to learn.
What Is an Optimization Algorithm?
An optimization algorithm determines how the network’s weights are updated after measuring the loss.
It answers this fundamental question:
“Given the current error, how should I adjust the weights to make the model better?”
Every optimizer tries to minimize the loss function by moving weights in the right direction using gradients.
Gradient Descent: The Core Idea
Gradient Descent is the foundation for all optimizers.
Formula:
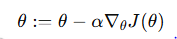
Where:
- θ = parameters (weights)
- α = learning rate
- J(θ) = loss function
- ∇J = gradient
It moves weights downhill toward the minimum of the loss surface.
Three main variants:
Batch Gradient Descent
Uses the entire dataset to compute a single update.
Pros
- Stable convergence
- Smooth updates
Cons
- Very slow on large datasets
- High memory usage
Used in small academic experiments, not ideal for real-world deep learning.
Stochastic Gradient Descent (SGD)
Updates weights after every training sample.
Pros
- Fast updates
- Works well on big datasets
- Helps escape local minima
Cons
- Noisy and unstable
- Loss curve fluctuates heavily
SGD is simple but often unstable without improvements.
Mini-Batch Gradient Descent (Most Popular)
Uses small batches (e.g., 32, 64, 128 samples).
The default method used in almost all modern deep learning training.
Pros
- Stable + fast
- Efficient on GPUs
- Smooth convergence
- Allows parallel training
Advanced Optimization Algorithms
Modern optimizers fix limitations of plain SGD.
SGD with Momentum
Momentum helps the model accelerate down slopes and smooth out updates.
Analogy:
Like pushing a ball downhill it builds speed.
Benefit:
- Prevents oscillations
- Faster convergence
- Better in deep networks
RMSProp (Root Mean Square Propagation)
Adjusts the learning rate independently for each parameter.
Best for:
- RNNs
- Non-stationary data
- Noisy gradients
Lecture 4 – Loss Functions in Deep Learning: MSE, Cross-Entropy & Optimization Explained
Adam (Adaptive Moment Estimation)
The most widely used optimizer in deep learning.
Adam = RMSProp + Momentum
Why Adam is powerful:
- Adaptive learning rate
- Smooth and stable convergence
- Works well on most tasks
- Requires little tuning
Used in:
- CNNs
- Transformers
- LLMs
- GANs
- Reinforcement Learning
This is the default optimizer in TensorFlow, PyTorch, JAX, etc.
https://www.tensorflow.org/api_docs/python/tf/keras/optimizers
AdamW (Adam + Weight Decay)
A better version of Adam.
Fixes Adam’s main weakness:
- Overfitting
- Bad generalization
Now used in all modern deep learning models including GPT, BERT, ViT, LLaMA, and Stable Diffusion.
Learning Rate: The Most Important Hyperparameter
The learning rate controls how big the weight updates are.
If learning rate is too high:
Model diverges
Loss explodes
Accuracy never improves
If too low:
Training becomes slow
Gets stuck in bad minima
Best practice:
Use learning rate schedulers (StepLR, CosineAnnealing, Warmup).
Choosing the Right Optimizer
| Task | Best Optimizer |
|---|---|
| General Deep Learning | Adam or AdamW |
| Image Classification | AdamW or SGD+Momentum |
| NLP / Transformers | AdamW |
| Reinforcement Learning | Adam |
| RNNs | RMSProp |
| Very Large Datasets | SGD+Momentum |
AdamW is currently the global standard.
https://www.tensorflow.org/api_docs/python/tf/keras/optimizers
Summary
Optimization algorithms control how a neural network updates its weights.
Using the right optimizer is crucial for fast, stable, and accurate training.
SGD provides the foundation, Momentum stabilizes updates, RMSProp adapts learning rates, and Adam/AdamW deliver the best performance across most modern deep learning tasks.
A good optimizer helps the model converge quickly a poor one can make learning impossible.
People also ask:
They minimize the loss function by updating model weights efficiently.
Because it combines momentum + adaptive learning rates, making training faster and more stable.
Mini-batch SGD uses small groups of samples, giving faster and smoother learning.
RMSProp is ideal for RNNs or noisy data
AdamW is the current best-performing optimizer for most neural network architectures.