
Introduction
In every deep learning model whether it’s classifying images, detecting spam emails, or predicting house prices learning only happens because of one critical component: the loss function.
A loss function measures how wrong a model’s predictions are.
It is the signal that tells the model:
“You are off by this much fix it.”
Without loss functions, training neural networks using gradient descent or backpropagation would be impossible.
This lecture explores how loss functions work, why they matter, and when to use the right one.
What Is a Loss Function?
A loss function quantifies the error between a model’s predictions and the actual target values.
Formally:
Loss = Measure of how far predictions are from the truth.
During training:
- The model predicts something
- The loss function evaluates accuracy
- Backpropagation uses the loss to adjust weights
- The optimizer tries to minimize this loss
The goal of every neural network is simple:
Minimize the loss → Improve accuracy.
Why Are Loss Functions Important?
Loss functions affect:
- How fast the model learns
- Whether training converges
- Whether gradients explode or vanish
- The accuracy of final predictions
- Whether the model generalizes well
Choosing the wrong loss function leads to:
Poor training
Incorrect gradients
Slow convergence
Overfitting or underfitting
Choosing the right one leads to:
Faster and stable learning
Better accuracy
Predictable gradients
Generalization on unseen data
Loss Functions for Regression
Regression means predicting continuous values, like:
- House prices
- Temperature
- Stock prices
- Sales prediction
Mean Squared Error (MSE)
Formula:
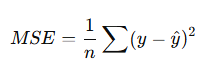
Why used?
- Penalizes large errors more
- Smooth gradient
- Works well with continuous outputs
Best for:
Price prediction, forecasting, continuous regression.
Mean Absolute Error (MAE)
Formula:
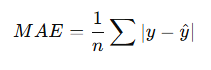
Why used?
- More robust to outliers
- Less sensitive than MSE
Best for:
Noisy data, high outlier environments.
Huber Loss
Combination of MSE + MAE.
Balances sensitivity and robustness.
Best for:
Regression tasks with moderate noise.
Loss Functions for Classification
Classification means predicting categories, like:
- Cat vs Dog
- Spam vs Not Spam
- Disease vs No Disease
- Multi-class image classification
Binary Cross-Entropy Loss
Used in binary classification.
Formula:
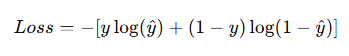
Why used?
- Works well with Sigmoid activation
- Produces sharp probability gradients
- Faster convergence
Example tasks:
- Spam detection
- Fraud detection
- Sentiment analysis
Categorical Cross-Entropy Loss
Used for multi-class classification.
Formula:
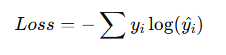
Requires:
Softmax activation in the output layer.
Example tasks:
- Image recognition (10 categories)
- Language classification
- Object detection
Sparse Categorical Cross-Entropy
Used when labels are integers (0,1,2…) instead of one-hot vectors.
Hinge Loss
Used in Support Vector Machines (SVMs).
Best for:
Maximum margin classifiers.
Kullback–Leibler Divergence (KL Divergence)
Measures the difference between two probability distributions.
Used in:
- Variational Autoencoders
- Reinforcement learning
- Language models
How Loss Functions Affect Training
Loss functions shape:
Gradient behavior
Some losses produce stable gradients; others cause exploding gradients.
Convergence speed
Cross-entropy trains faster than MSE for classification.
Model performance
The right loss ensures correct optimization.
How to Choose the Right Loss Function
| Problem Type | Recommended Loss |
|---|---|
| Binary Classification | Binary Cross-Entropy |
| Multi-Class Classification | Categorical Cross-Entropy |
| Regression (Normal Data) | MSE |
| Regression (Noisy Data) | MAE |
| Outlier-Resistant Regression | Huber Loss |
| Probability Distribution Learning | KL Divergence |
Example – Regression (House Prices)
Target price: ₹10,000,000
Model predicts: ₹12,000,000
Loss using MSE:
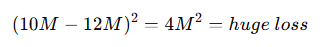
This large loss forces the model to correct aggressively.
Example – Binary Classification
Email Classification
Actual: Spam → 1
Model predicts: 0.1
Binary cross-entropy loss will be very high, pushing model to increase the spam probability.
Loss Surface Intuition
Imagine a 3D bowl-shaped surface.
The optimizer rolls downhill to reach the lowest point — the global minimum.
Bad loss surface =
Many local minima
Vanishing gradients
Good loss surface =
Smooth curves
Global minima accessible
Cross-entropy produces cleaner loss surfaces.
Summary
Loss functions tell a neural network how wrong its predictions are.
They provide the error signal that drives backpropagation and weight updates.
Choosing the right loss function is essential for stable learning, faster convergence, and high accuracy.
Regression tasks rely on MSE, MAE, or Huber, while classification tasks use Binary Cross-Entropy or Categorical Cross-Entropy.
A good loss function guides the model toward better predictions a bad one can stop learning entirely.
People also ask:
A loss function is a mathematical formula that measures error between predicted and actual values to guide learning.
Cross-Entropy is the most widely used for both binary and multi-class classification.
MSE penalizes large errors more heavily, while MAE treats all errors equally.
Cross-entropy produces better gradients for probability outputs and leads to faster training.
KL divergence measures the distance between probability distributions, used in VAEs, RL, and language modeling.


