Deep Learning: Complete Guide for Semester Exams
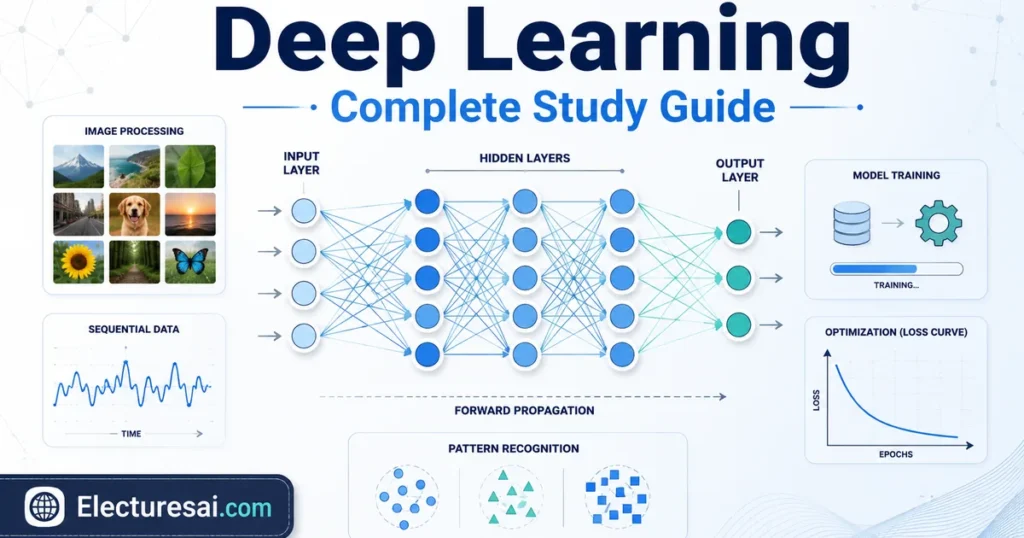
Deep Learning is an important subject for students of Computer Science, Data Science, Software Engineering, and related degree programs. It explains how multilayer neural networks learn patterns from data and use those patterns to perform tasks such as image classification, speech recognition, text processing, forecasting, and anomaly detection.
Students often find this subject difficult because it combines mathematical ideas, network architecture, optimization, and practical model training. Terms such as weights, biases, activation functions, gradients, backpropagation, convolution, and regularization may appear disconnected when you first study them.
They become much easier when you understand the complete learning process. A neural network receives input, produces a prediction, measures its error, and adjusts its internal parameters. This process repeats until the network becomes better at the assigned task.
This guide explains the major concepts of Deep Learning in clear academic language. It is designed to help you prepare for semester exams, MCQs, short questions, diagrams, comparisons, and descriptive answers.
Table of Contents
- What Is Deep Learning?
- Key Concepts in Deep Learning
- Important Deep Learning Architectures
- Important Topics for Exam Preparation
- How to Study Deep Learning Effectively
- Common Mistakes Students Make
- Expert Tips for Scoring High
- Practice MCQs
- Frequently Asked Questions
- Conclusion
What Is Deep Learning?
Deep Learning is a branch of machine learning that uses neural networks containing multiple processing layers to learn useful representations and patterns from data.
The word deep refers to the presence of several layers between the input and output. These layers gradually transform raw data into more useful features.
Consider an image-classification system. The first layers may detect simple features such as edges and corners. Middle layers may combine those edges into shapes or textures. Deeper layers may recognize larger structures such as eyes, wheels, faces, or complete objects.
This automatic feature learning is one of the main strengths of Deep Learning. In many traditional methods, a developer must manually decide which features should be extracted. A deep network can learn many of those features directly from examples.
Deep Learning and Traditional Machine Learning
Traditional machine-learning systems often depend heavily on manually selected features. A person may decide which measurements, statistics, or patterns should be provided to the model.
Deep Learning can learn several levels of representation automatically. This is especially useful when working with complex data such as images, sound, video, and natural language.
However, Deep Learning is not always the best solution. It may require large datasets, considerable computation, careful tuning, and longer training time. Simpler methods may perform better when the dataset is small or the relationships are straightforward.
Why Is Deep Learning Important?
Deep Learning is used in many practical systems, including:
- Image classification and object detection
- Medical-image analysis
- Speech recognition
- Text classification and translation
- Recommendation systems
- Fraud and anomaly detection
- Weather and demand forecasting
- Industrial quality inspection
- Autonomous navigation
- Scientific data analysis
The subject is also important academically because it connects programming, linear algebra, probability, statistics, calculus, and optimization.
Key Concepts in Deep Learning
Artificial Neuron
An artificial neuron is the basic computational unit of a neural network. It receives one or more input values, multiplies each input by a weight, adds a bias, and applies an activation function.
Text-described neuron diagram:
Inputs → Weighted sum plus bias → Activation function → Output
The weighted sum can be represented conceptually as:
z = (input₁ × weight₁) + (input₂ × weight₂) + … + bias
The activation function then converts this value into the neuron’s output.
Weights and Biases
Weights determine the influence of each input. A large positive weight may strengthen an input’s contribution, while a negative weight may reduce or reverse it.
The bias allows the neuron to shift its decision boundary. Without a bias, the neuron would be more restricted in the patterns it could represent.
Weights and biases are the trainable parameters of a neural network. Training changes these values so that the model produces better predictions.
Layers of a Neural Network
A typical feedforward neural network contains three types of layers:
- Input layer: Receives the original features.
- Hidden layers: Transform the information and learn internal representations.
- Output layer: Produces the final prediction.
A network with several hidden layers is described as deep.
Text-described network diagram:
Input features → Hidden layer 1 → Hidden layer 2 → Hidden layer 3 → Output prediction
Activation Functions
An activation function introduces non-linearity into a neural network. Without non-linear activation functions, several stacked layers would behave like one linear transformation and would be unable to learn many complex patterns.
ReLU
The Rectified Linear Unit returns zero for negative inputs and returns the original value for positive inputs.
ReLU is widely used in hidden layers because it is computationally simple and often supports effective gradient-based training.
Sigmoid
The sigmoid function maps an input to a value between 0 and 1.
It is commonly used in the output layer of a binary-classification model where the result is interpreted as a probability. In deep hidden layers, it may contribute to vanishing gradients.
Tanh
The hyperbolic tangent function produces outputs between -1 and 1.
It is centred around zero, but it may also suffer from vanishing gradients when inputs fall into saturated regions.
Softmax
Softmax converts a group of output scores into a probability distribution whose values add up to one.
It is commonly used for multiclass classification where each example belongs to one class.
Forward Propagation
Forward propagation is the process of passing input data through the network to produce a prediction.
At each layer, the network:
- Receives values from the previous layer.
- Calculates weighted sums.
- Adds biases.
- Applies activation functions.
- Sends the resulting values to the next layer.
The final layer produces the model’s prediction.
Loss Function
A loss function measures how far the model’s prediction is from the correct target.
A small loss indicates that the prediction is close to the target. A large loss indicates greater error.
Common loss functions include:
- Mean squared error: Often used for regression.
- Binary cross-entropy: Commonly used for binary classification.
- Categorical cross-entropy: Commonly used for multiclass classification.
The choice of loss function should match the type of prediction problem.
Backpropagation
Backpropagation calculates how much each trainable parameter contributed to the prediction error.
It begins at the output layer and moves backward through the network. Using the chain rule of calculus, it calculates gradients for weights and biases.
Text-described training direction:
Forward pass: Input → Prediction → Loss
Backward pass: Loss → Gradients → Parameter updates
Backpropagation does not directly update the parameters. It calculates the gradients that an optimization algorithm uses to perform the updates.
Gradient Descent
Gradient descent is an optimization method used to reduce the loss.
A gradient indicates the direction in which a parameter should change. The optimizer usually moves the parameter in the opposite direction of the gradient because that direction tends to reduce the loss.
Batch Gradient Descent
Batch gradient descent calculates an update using the complete training dataset. It can be stable but may be slow and memory-intensive for large datasets.
Stochastic Gradient Descent
Stochastic gradient descent updates the model using one training example at a time. Its updates can be noisy, but that noise sometimes helps exploration during training.
Mini-Batch Gradient Descent
Mini-batch gradient descent uses a small group of examples for each update. It balances computational efficiency with reasonably stable gradient estimates and is widely used in practice.
Learning Rate
The learning rate controls the size of each parameter update.
If it is too small, training may be extremely slow. If it is too large, the optimizer may overshoot useful solutions, cause unstable loss, or fail to converge.
Learning-rate schedules can reduce the learning rate during training. This allows larger steps early in training and finer adjustments later.
Epochs, Batches, and Iterations
An epoch is one complete pass through the training dataset.
A batch is a subset of training examples processed together.
An iteration is one parameter update. If a dataset is divided into 100 mini-batches, one epoch contains 100 iterations.
Training, Validation, and Test Sets
The training set is used to learn model parameters.
The validation set is used to compare architectures, tune hyperparameters, and monitor generalization during development.
The test set is used for final evaluation after major modeling decisions have been completed.
Using the test set repeatedly during development can produce an overly optimistic estimate of performance.
Underfitting and Overfitting
Underfitting occurs when a model is too simple, poorly trained, or unable to capture important patterns. It performs poorly on both training and unseen data.
Overfitting occurs when a model learns the training data too closely, including noise or accidental details. It may achieve excellent training performance but perform poorly on validation or test data.
Regularization
Regularization techniques reduce overfitting and improve generalization.
L1 and L2 Regularization
L1 and L2 regularization add a penalty for large weights to the loss function.
L1 regularization can encourage some weights to become exactly zero. L2 regularization discourages very large weights and often produces smoother parameter values.
Dropout
Dropout temporarily removes a random proportion of neuron outputs during training.
This prevents the network from depending too heavily on a small group of neurons and encourages more distributed representations.
Early Stopping
Early stopping monitors validation performance and ends training when improvement stops for a selected period.
This can prevent the model from continuing to fit training-specific noise.
Data Augmentation
Data augmentation creates modified training examples while preserving their labels.
For images, transformations may include rotation, flipping, cropping, scaling, or brightness adjustment. The selected transformations must remain realistic for the task.
Batch Normalization
Batch normalization standardizes intermediate activations using statistics calculated from a mini-batch and then applies learned scaling and shifting parameters.
It can stabilize training, support larger learning rates, and reduce sensitivity to parameter initialization. Its training and inference behavior are not exactly the same.
Weight Initialization
Weights should not all begin with the same value. Identical initialization can cause neurons to learn identical features.
Methods such as Xavier or Glorot initialization and He initialization choose starting values based on layer size and activation behavior.
Vanishing and Exploding Gradients
In deep or recurrent networks, gradients may become extremely small as they move backward. This is called the vanishing-gradient problem and can prevent early layers from learning effectively.
Gradients may also become extremely large, producing unstable updates. This is called the exploding-gradient problem.
Suitable activations, careful initialization, normalization, residual connections, gating mechanisms, and gradient clipping can help address these problems.
Important Deep Learning Architectures
Feedforward Neural Networks
A feedforward neural network passes information from input to output without creating feedback loops.
Fully connected feedforward networks are commonly used for structured datasets, classification, regression, and introductory neural-network problems.
Convolutional Neural Networks
Convolutional Neural Networks, commonly called CNNs, are designed to process grid-like data such as images.
A convolutional layer uses small learnable filters that move across the input. Each filter detects a particular local pattern and produces a feature map.
Text-described CNN pipeline:
Image → Convolution → Activation → Pooling → Deeper features → Classifier
Filters and Feature Maps
A filter is a small matrix of trainable values. During convolution, it is applied to local regions of the input.
Different filters may learn to respond to edges, textures, colours, shapes, or more complex features.
Stride
Stride determines how many positions the filter moves at each step. A larger stride usually produces a smaller output feature map.
Padding
Padding adds values around the border of an input. It can preserve more border information and help control the spatial size of the output.
Pooling
Pooling reduces the spatial dimensions of feature maps.
Max pooling keeps the largest value within each selected region. Average pooling calculates the mean value. Pooling reduces computation and can make features less sensitive to small shifts.
Recurrent Neural Networks
Recurrent Neural Networks, or RNNs, are designed for sequential data.
An RNN maintains a hidden state that carries information from earlier positions in the sequence. This makes it suitable for time series, text, speech, and other ordered data.
Basic RNNs may struggle with long-term dependencies because gradients can vanish or explode across many time steps.
LSTM and GRU Networks
Long Short-Term Memory networks use gates to control what information is stored, forgotten, and passed forward.
Gated Recurrent Units use a simpler gating design while serving a similar purpose.
These architectures are better than basic RNNs at preserving useful information across longer sequences.
Attention and Transformer Networks
Attention allows a model to focus on the most relevant parts of an input when producing an output.
Transformer networks rely heavily on attention rather than recurrent processing. They can model relationships between distant sequence positions and support efficient parallel processing during training.
Autoencoders
An autoencoder learns to reconstruct its input.
The encoder compresses the input into a smaller representation, while the decoder attempts to rebuild the original data.
Autoencoders can be used for dimensionality reduction, feature learning, anomaly detection, and denoising.
Transfer Learning
Transfer learning begins with a model that has already learned useful features from another dataset.
The existing model may be used as a feature extractor or fine-tuned for a new task. This approach can reduce training time and improve performance when the new dataset is limited.
Important Topics for Deep Learning Exam Preparation
Give special attention to the following topics:
- Definition and scope of Deep Learning
- Artificial neuron and perceptron
- Weights, biases, and layers
- Linear and non-linear transformations
- ReLU, sigmoid, tanh, and softmax
- Forward propagation
- Loss functions
- Backpropagation and the chain rule
- Gradient descent variants
- Learning rate and learning-rate schedules
- Epochs, batches, and iterations
- Training, validation, and test sets
- Underfitting and overfitting
- Dropout, L1, and L2 regularization
- Early stopping and data augmentation
- Batch normalization
- Weight initialization
- Vanishing and exploding gradients
- CNN layers, filters, stride, padding, and pooling
- RNN, LSTM, and GRU architectures
- Attention and transformers
- Autoencoders and transfer learning
- Classification and regression evaluation metrics
Examiners may describe a training situation instead of asking for a direct definition. For example, steadily decreasing training loss with increasing validation loss is a common sign of overfitting.
Step-by-Step: How to Study Deep Learning Effectively
Step 1: Revise the Mathematical Foundation
Review vectors, matrices, matrix multiplication, derivatives, the chain rule, probability, and basic statistics. You do not need advanced mathematics for every question, but you should understand what gradients and matrix operations represent.
Step 2: Understand One Neuron First
Learn how inputs, weights, bias, and an activation function produce an output. Do not move directly to large architectures before this process is clear.
Step 3: Follow the Training Loop
Memorize the logical sequence:
- Initialize parameters.
- Perform forward propagation.
- Calculate the loss.
- Perform backpropagation.
- Update the parameters.
- Repeat for multiple batches and epochs.
Step 4: Compare Activation Functions
Create a table showing output range, common use, benefits, and limitations of ReLU, sigmoid, tanh, and softmax.
Step 5: Study Architectures by Data Type
Connect common architectures with the kind of data they process:
- Fully connected network — structured features
- CNN — images and spatial data
- RNN, LSTM, or GRU — sequential data
- Transformer — attention-based sequence processing
- Autoencoder — reconstruction and representation learning
Step 6: Practice Output-Size Questions
For CNNs, practice how filter size, padding, and stride affect the dimensions of feature maps.
Step 7: Learn Through Training Scenarios
Ask what you would change if training is unstable, validation performance is poor, gradients vanish, or the dataset is small.
Step 8: Attempt Timed MCQs
After topic-wise revision, attempt a mixed quiz under a timer. Review the explanation for every wrong answer.
Common Mistakes Students Make
Confusing Parameters With Hyperparameters
Weights and biases are learned parameters. Learning rate, batch size, number of layers, and dropout rate are selected hyperparameters.
Thinking Backpropagation and Gradient Descent Are the Same
Backpropagation calculates gradients. Gradient descent uses those gradients to update parameters.
Using Softmax for Every Output
Softmax is commonly used for mutually exclusive multiclass classification. It is not the standard output for regression or independent multilabel classification.
Assuming More Layers Always Improve Performance
A deeper network may be harder to train and may overfit. Architecture should match the task, data, and available resources.
Evaluating the Model on Training Data Only
Strong training performance does not prove that the model will generalize. Validation and test data are required for meaningful evaluation.
Confusing Epoch and Iteration
An epoch processes the complete training dataset once. An iteration processes one batch and performs one update.
Ignoring Data Quality
A complex network cannot reliably correct incorrect labels, biased sampling, data leakage, or irrelevant inputs. Data preparation remains essential.
Applying Unrealistic Data Augmentation
A transformation should preserve the correct label. An augmentation that changes the actual meaning of an example can damage training.
Expert Tips for Scoring High in Deep Learning
- Begin descriptive answers with a direct definition.
- Draw a labelled neuron or training-loop diagram where appropriate.
- Explain the difference between forward and backward propagation clearly.
- Use tables for activation functions and optimization methods.
- Relate CNNs to spatial data and recurrent networks to sequences.
- Explain both the purpose and limitation of each technique.
- Include a practical example in architecture questions.
- Practise identifying overfitting from training and validation curves.
- Write parameter-update steps in the correct sequence.
- Review mistakes through mixed MCQs before the exam.
Practice MCQs
MCQ 1
Which components are normally learned during neural-network training?
A. Weights and biases
B. Input labels and batch names
C. Number of classes and file names
D. Training and test folders
Correct Answer: A. Weights and biases
Explanation: Weights and biases are trainable parameters adjusted to reduce the loss. The other options describe dataset information or organization rather than learned parameters.
MCQ 2
Why are non-linear activation functions used in hidden layers?
A. To remove all trainable parameters
B. To allow the network to learn complex relationships
C. To prevent forward propagation
D. To make every output identical
Correct Answer: B. To allow the network to learn complex relationships
Explanation: Non-linear activation functions enable stacked layers to represent complex decision boundaries. Without them, multiple layers would behave like a linear transformation.
MCQ 3
What is the main role of backpropagation?
A. To divide the dataset into classes
B. To calculate gradients of the loss
C. To select file formats
D. To remove the output layer
Correct Answer: B. To calculate gradients of the loss
Explanation: Backpropagation determines how the loss changes with respect to trainable parameters. An optimizer then uses these gradients to update the parameters.
MCQ 4
Which architecture is especially suitable for image data?
A. Convolutional Neural Network
B. Simple linear equation
C. Database index
D. Decision table
Correct Answer: A. Convolutional Neural Network
Explanation: CNNs use local filters and shared parameters to learn spatial features from images. The other options are not deep-network architectures designed for visual data.
MCQ 5
Which condition is a common sign of overfitting?
A. Poor performance on both training and validation data
B. Strong training performance but weak validation performance
C. Identical loss before and after training
D. Absence of trainable parameters
Correct Answer: B. Strong training performance but weak validation performance
Explanation: An overfitted model learns the training data too specifically and does not generalize well. Poor performance on both sets is more commonly associated with underfitting.
Frequently Asked Questions
What is Deep Learning in simple words?
Deep Learning is a machine-learning approach that uses neural networks with several layers. These layers learn increasingly useful representations from training data.
Is Deep Learning difficult to study?
It can feel difficult because it combines mathematics, programming, and model design. It becomes manageable when you study one neuron, forward propagation, loss, backpropagation, and optimization in sequence.
What mathematics is required for Deep Learning?
You should understand vectors, matrices, basic probability, derivatives, and the chain rule. More advanced mathematics becomes useful when studying optimization and model architecture in greater depth.
What is the difference between a parameter and a hyperparameter?
Parameters, such as weights and biases, are learned from data. Hyperparameters, such as learning rate, batch size, and layer count, are selected before or during model development.
Why is ReLU commonly used in hidden layers?
ReLU is simple to calculate and does not saturate for positive inputs. It often supports more effective gradient flow than sigmoid or tanh in deep hidden layers.
What is the difference between CNN and RNN?
CNNs are designed to learn local spatial patterns and are widely used for images. RNNs process ordered sequences and maintain information from earlier time steps.
How can overfitting be reduced?
Common methods include dropout, L1 or L2 regularization, early stopping, data augmentation, simpler architecture, and additional representative data.
How should I prepare Deep Learning MCQs?
Revise definitions, training steps, activation functions, optimization methods, architectures, and common problems. Attempt topic-wise questions first and finish with mixed timed practice.
Conclusion
Deep Learning explains how multilayer neural networks learn useful patterns from data. The core process involves forward propagation, loss calculation, backpropagation, and parameter updates.
The subject becomes easier when you connect each technique with the problem it solves. Activation functions provide non-linearity, optimizers reduce loss, regularization improves generalization, CNNs process spatial data, and recurrent or attention-based networks process sequences.
Prepare diagrams, comparison tables, architecture summaries, and training scenarios. Combine this theory with regular MCQ practice to improve your understanding and semester-exam performance.
Ready to Test Your Knowledge?
If you want to practice Deep Learning MCQs with answers, explanations, and exam-focused questions, continue your preparation on TestInFlow.
Practice Deep Learning MCQs on TestInFlow →
Want to Explore More Topics?
eLecturesAI covers university subjects with detailed lecture notes, study guides, MCQs, and exam-preparation resources.