Explore information extraction, named entity recognition and relation extraction using dependency and constituency grammars.
Most text on the web is unstructured. Articles, news, emails and social media posts are easy for humans to read but difficult for machines to query directly. Information extraction aims to bridge this gap by turning unstructured sentences into structured records: entities, relations and events that can populate tables and knowledge graphs.
This lecture introduces information extraction in NLP, with a particular focus on named entity recognition, the end to end extraction pipeline and relation extraction using dependency and constituency grammars. The final goal is to show how parsing from previous lectures becomes useful for building higher level semantic structures.
What is information extraction in NLP
Information extraction turns free text into structured data. Given a sentence like.
“Apple acquired Beats Electronics in 2014 for $3 billion.”
an information extraction system tries to identify entities such as “Apple”, “Beats Electronics” and “2014” and then infer relations like ACQUISITION(Apple, Beats Electronics, 2014, $3 billion).
Typical information extraction subtasks.
- Named entity recognition. find mentions of people, organisations, locations, dates, products and other entity types.
- Relation extraction. detect semantic relations between entities such as works for, born in, located in, acquired, part of.
- Event extraction. identify events such as meetings, attacks, mergers and link them to participants and times.
- Slot or template filling. populate a structured template with fields like company name, CEO, headquarters, revenue.
These steps support downstream applications. knowledge graph construction, question answering, compliance monitoring, financial analytics and many more.
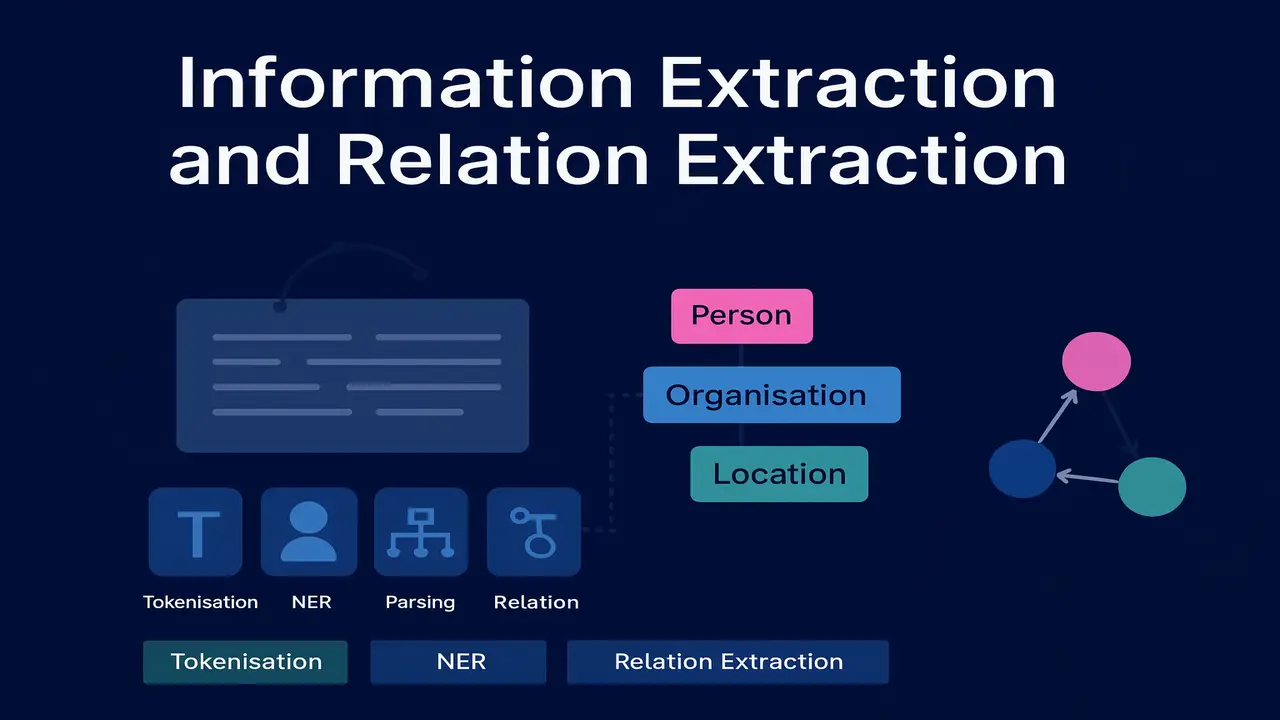
Named entity recognition. core idea
Named entity recognition (NER) is usually the first stage in information extraction. It labels spans of tokens with semantic categories like PERSON, ORGANIZATION, LOCATION, DATE, MONEY and so on.
For example.
“[Barack Obama]_PERSON was born in [Honolulu]_LOCATION in [1961]_DATE.”
Modern NER is typically framed as a sequence labelling problem. each token gets a tag such as B-PER (begin person), I-PER (inside person) or O (outside any entity). Earlier lectures on POS tagging and HMMs give the mathematical background for these models.
Conceptual steps in NER.
- Preprocess text. tokenize, normalise case, sometimes perform POS tagging.
- Extract features or embeddings. word shapes, prefixes, suffixes, surrounding context, character patterns or contextual word embeddings.
- Apply a sequence model. historically Hidden Markov Models, Maximum Entropy Markov Models and Conditional Random Fields, and more recently BiLSTM or transformer based taggers.
- Decode the best sequence of labels and combine them into entity spans.
Well known tools such as the Stanford NER tagger and CoreNLP NER component follow this general architecture.
Lecture 5 – Hidden Markov Models and POS Tagging in Natural Language Processing
Information extraction pipeline
In practice, information extraction is rarely a single step. It is a pipeline with several NLP components connected together. A typical pipeline for sentence level extraction might look like this.
- Document preprocessing
- Sentence segmentation and tokenisation.
- Normalisation and optional lemmatisation.
- Removal of obviously irrelevant parts such as boilerplate.
- Linguistic analysis
- POS tagging (as introduced in Lecture 5).
- Dependency or constituency parsing (Lectures 6 and 7).
- Named entity recognition
- Label spans that correspond to names, locations, organisations, dates, numbers and other entity types.
- Coreference resolution (optional in this course)
- Link different mentions that refer to the same real world entity, such as “Barack Obama”, “Obama” and “the president”.
- Relation and event extraction
- Identify semantic relations between entities using patterns, dependency paths or learned models.
- Optionally identify event triggers and arguments.
- Knowledge representation
- Store extracted entities and relations in a database, triple store or graph representation.
At each stage, parsing and POS tags provide structural information that helps relation extraction move beyond simple keyword matching.
Relation extraction using dependency and constituency parses
Relation extraction tries to answer questions like “who works where”, “which company acquired which company”, or “what city is located in which country”. Many of these relations correspond closely to syntactic configurations.
Dependency parsing represents each sentence as a labelled directed graph where words are nodes and edges represent grammatical relations such as subject, object or modifier. Constituency parsing represents the phrase structure tree of the sentence.
Both views are useful.
Dependency based relation extraction
For the sentence.
“Google acquired YouTube in 2006.”
A dependency parse will typically mark “acquired” as the head verb with nsubj(acquired, Google) and obj(acquired, YouTube) plus an oblique modifier for the year. A simple rule can then capture an ACQUISITION(Company, Company) relation whenever an acquisition verb has organisation subject and object.
Advantages.
- Dependency paths are compact and often language independent at a conceptual level.
- Shortest dependency path between two entities is a strong feature for relation classifiers.
Constituency based relation extraction
Constituency trees group words into phrases like noun phrases and verb phrases. Patterns such as “[NP PERSON] works at [NP ORGANIZATION]” can be expressed at the phrase level. This is useful for rule based extraction or as features for machine learning models.
In both cases, entity types from NER constrain which pairs of spans are considered as candidates. A relation classifier or rule system then decides which candidate pairs express a particular relation.
Approaches to information and relation extraction
There are three broad families of approaches: rule based, supervised learning and distant or weak supervision.
- Rule based extraction Handwritten patterns using regular expressions, lexical triggers and parse tree templates. Example.
- For employment relations: patterns like “[PERSON] works at [ORG]”, “[PERSON] joined [ORG]”, “[ORG] hired [PERSON]”.
- For location relations: “[ORG] is based in [LOCATION]”, “[CITY], [COUNTRY]”.
Cons. brittle, labour intensive, poor coverage across domains and languages. - Supervised machine learning Use annotated corpora where entities and relations are labelled. Represent each entity pair with features (lexical, dependency path, surrounding words, entity types) and train a classifier such as logistic regression, SVM or a neural network. Pros. more robust, can capture subtle patterns, easier to adapt by retraining.
Cons. requires expensive labelled data for each relation type and domain. - Distant or weak supervision Use an existing knowledge base like Freebase or Wikidata to automatically generate training examples. If a knowledge base says
born_in(Albert_Einstein, Ulm), then any sentence mentioning both entities becomes a positive training instance. Negative instances can be constructed from unrelated pairs. Pros. reduces manual annotation effort, scales to many relations.
Cons. introduces noise because sentences can mention two entities without expressing the target relation.
Recent research often combines neural sequence models with dependency based features, but the underlying tasks remain the same.
For a broader view of the information extraction pipeline, including relation and event extraction, see the information extraction chapter in Speech and Language Processing.
Use cases. knowledge graph construction and beyond
One of the most visible applications of information and relation extraction is the construction of knowledge graphs. A knowledge graph represents entities as nodes and relations as edges, often with types and attributes.
Examples.
- Search engines use large knowledge graphs to answer factual queries directly (“Who is the CEO of Apple?”) without forcing users to click through many documents.
- Digital assistants use extracted relations to answer questions like “What is the capital of France?” or “Which movies did Christopher Nolan direct?”
- Enterprises build internal knowledge graphs linking customers, products, transactions and support issues for analytics and recommendation.
Information extraction is also used for.
- Compliance monitoring. automatically scanning news and reports for relations linking organisations to sanctions lists or high risk activities.
- Scientific literature mining. extracting gene disease associations or drug protein interactions from biomedical articles.
- Social media analytics. identifying entities and relations that describe public opinion, event participation or product co mentions.
In all cases, NER, POS tagging and parsing from earlier lectures are key building blocks.
- Real examples
You can present this compact list in a “Real world examples” section.
- Extracting company–acquisition relations from technology news to populate a mergers and acquisitions database.
- Building a knowledge graph of patients, diseases, medications and side effects from clinical notes for hospital analytics.
- Mining scientific papers to find pairs of chemicals and materials that co appear in synthesis reactions, supporting materials discovery.
- Analysing social media posts to link influencers, brands and events in a marketing knowledge graph.
- Extracting person–organization and location relations from CVs and profiles to support automatic candidate search and matching.
Step by step algorithm explanation (simple IE pipeline)
Step 1. Input a collection of raw documents.
Step 2. Preprocess each document:
- perform sentence segmentation and tokenisation.
- run POS tagging and dependency parsing using an NLP toolkit.
Step 3. Run a named entity recognizer to mark entity spans and types such as PERSON, ORGANIZATION, LOCATION and DATE.
Step 4. Generate candidate pairs of entities that occur in the same sentence or within a fixed window.
Step 5. For each candidate pair, extract features:
- entity types and head words.
- words between the entities and around them.
- shortest dependency path connecting the two entities.
- relevant parse tree fragments, if using constituency structure.
Step 6. Apply a rule set or a trained classifier to decide which relation, if any, holds between the two entities.
Step 7. Store accepted relations as structured tuples or graph edges, together with offsets pointing back to the original text.
Step 8. Optionally perform cross sentence aggregation and coreference resolution to merge duplicates and build a coherent knowledge graph.
Code examples (Python with spaCy style pseudocode)
Below is an illustrative example using a spaCy-like API to perform NER and simple pattern based relation extraction. It is meant as teaching code; adapt to your environment.
import spacy
# Load an English NLP model with NER, POS and dependency parsing
nlp = spacy.load("en_core_web_sm")
text = """
Apple acquired Beats Electronics in 2014 for $3 billion.
Barack Obama was born in Honolulu in 1961.
"""
doc = nlp(text)
# 1) Print named entities
print("Named entities:")
for ent in doc.ents:
print(ent.text, "->", ent.label_)
# 2) Simple rule-based relation extraction examples
relations = []
for sent in doc.sents:
# Find organisation-organisation acquisitions
orgs = [ent for ent in sent.ents if ent.label_ == "ORG"]
if len(orgs) >= 2:
for token in sent:
if token.lemma_.lower() in {"acquire", "buy", "purchase"}:
relations.append(("ACQUISITION", orgs[0].text, orgs[1].text))
# Find person-location birth relations
persons = [ent for ent in sent.ents if ent.label_ == "PERSON"]
locs = [ent for ent in sent.ents if ent.label_ in {"GPE", "LOC"}]
for token in sent:
if token.lemma_.lower() == "bear" or token.text.lower() == "born":
if persons and locs:
relations.append(("BORN_IN", persons[0].text, locs[0].text))
print("\nExtracted relations:")
for r in relations:
print(r)This small script:
- runs NER and parsing;
- prints recognised entities;
- applies simple pattern rules using lemmas and entity types to extract ACQUISITION and BORN_IN relations.
Summary
Information extraction in NLP transforms raw text into structured knowledge by identifying entities and the relations between them. Named entity recognition provides the basic building blocks, while dependency and constituency parsing reveal the grammatical connections that relation extraction exploits. Rule based patterns, supervised models and distant supervision offer different ways to learn how entities interact in real text.
These techniques underpin knowledge graph construction, question answering, compliance monitoring and many other high value applications. For students who have already studied POS tagging, parsing and text representation, information extraction is a natural next step because it shows how those tools combine into end to end semantic systems.
Next Lecture 13 – Machine Translation: From Rule-Based to Neural
People also ask:
Information extraction is the task of automatically converting unstructured text into structured data. It identifies entities, relations and events from sentences and stores them as tuples or graphs that can be queried and analyzed more easily than raw text.
Named entity recognition is usually the first step in an information extraction pipeline. It finds spans in the text that refer to people, organizations, locations, dates, numbers and other semantic categories, providing the entity nodes that relation and event extraction will later connect.
Relation extraction detects semantic relationships between entities, such as works for, located in or acquired. Dependency and constituency parses provide the syntactic structure that reveals how entities are connected in a sentence, making it easier to design rules or features that capture those relations.
Common approaches include rule based systems that use patterns and regular expressions, supervised machine learning models trained on annotated corpora, and distant supervision methods that use existing knowledge bases to automatically generate training data. Recent work often combines neural sequence models with dependency based features.
Once entities and relations are extracted from text, they can be stored as nodes and edges in a knowledge graph. Over time, extraction from many documents accumulates a large graph that captures who did what, when and where. Search engines, digital assistants and enterprise analytics platforms use these graphs to answer queries and support decision making.