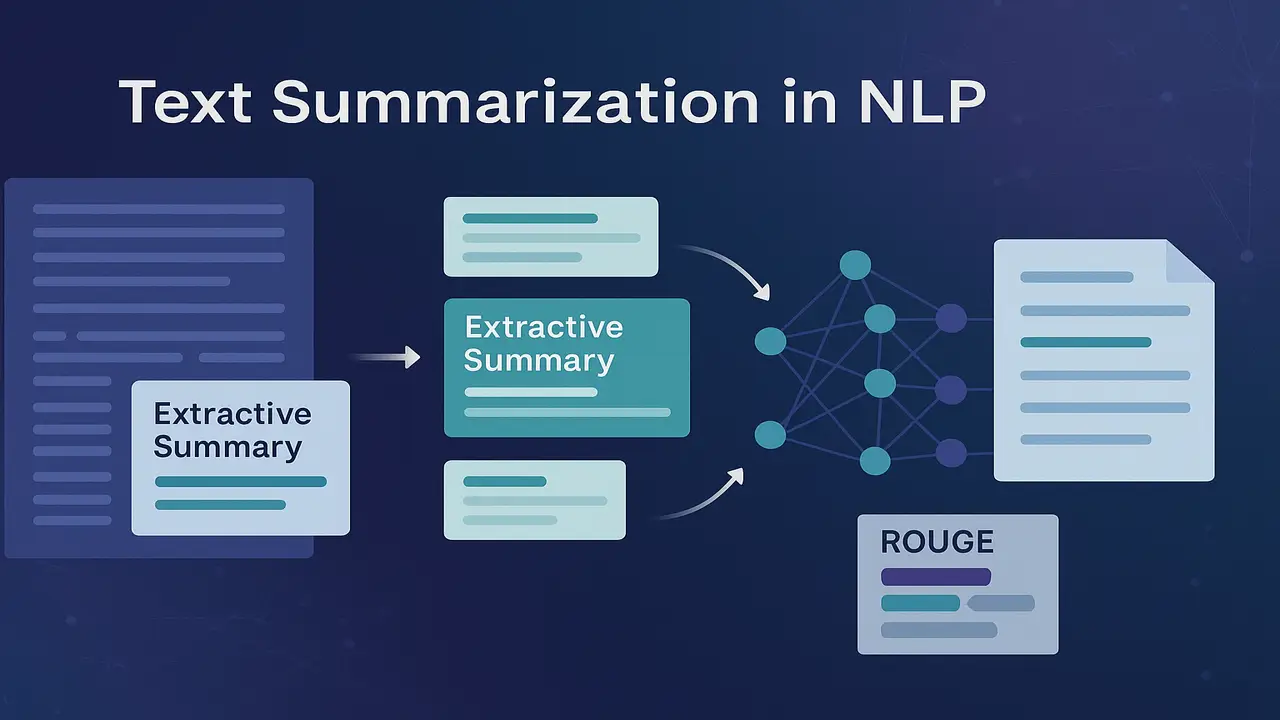
Extractive and abstractive text summarization techniques with examples and evaluation metrics like ROUGE.
As the volume of digital text continues to grow, it is no longer practical for humans to read every article, report or judgment in full. Text summarization in NLP addresses this challenge by automatically producing shorter versions of documents that preserve the most important information. Summaries help readers scan news feeds, understand research papers quickly and review long legal or technical documents.
This lecture introduces the main paradigms of text summarization. extractive versus abstractive. We discuss graph based extractive methods inspired by TextRank, give an intuitive view of ROUGE evaluation and explore key application areas. Throughout, we connect summarization to earlier lectures on text classification and language modelling.
What is text summarization in NLP
Text summarization in NLP is the task of generating a concise version of a document while retaining its core meaning and main points. Summaries can be.
. single document. summarising one article or report
. multi document. combining information from several related documents into one coherent summary
Summaries may be designed for different purposes.
. indicative. giving an overview so the reader can decide whether to read the full document
. informative. capturing the main findings, arguments or events in some detail
Unlike simple snippet extraction, a good summary should be coherent, non redundant and focussed on the central content, not on background or repeated details.
Extractive versus abstractive summarization
There are two broad approaches to text summarization.
Extractive summarization
Extractive methods select and concatenate existing units from the source document, usually sentences or sometimes paragraphs. They never generate new phrases. Instead, they rank sentences by importance and then pick the top k sentences that best represent the document under a length constraint.
Advantages.
. relatively easy to implement and control
. grammaticality is usually high because sentences are taken from the original text
. works well when the document already has clear, well written sentences
Limitations.
. summaries may contain redundancy if multiple selected sentences repeat similar content
. cannot paraphrase or compress complex sentences
. sometimes include local references (“this result”, “as shown above”) that are unclear when taken out of context
Abstractive summarization
Abstractive methods try to generate new sentences that may paraphrase, fuse or compress information from multiple parts of the original text. Neural sequence to sequence models with attention and transformers are typical architectures.
Advantages.
. can produce more natural, concise summaries
. can rephrase and restructure content, combine several sentences into one
. better aligned with how human experts write summaries or abstracts
Limitations.
. more difficult to train and evaluate
. risk of hallucination. the model may invent facts not present in the source
. requires substantial training data and careful control for sensitive domains
In practice, hybrid approaches that combine extractive pre selection with abstractive rewriting are becoming common, especially for long documents.
Graph based extractive summarization. TextRank idea
Many extractive summarizers rely on scoring each sentence individually using features similar to those used in text classification. For example, sentences may be scored based on TF IDF, position in the document, presence of title words or cue phrases. Lecture nine on text classification introduced these concepts.
Graph based methods like TextRank take a different view. Instead of scoring sentences independently, they model how sentences relate to one another in a graph. The high level idea is.
- Represent each sentence as a node in a graph.
- Connect two sentences with an edge if they are similar, typically based on lexical overlap or cosine similarity of TF IDF vectors.
- Run a ranking algorithm similar to PageRank to assign importance scores to sentences. Sentences that are strongly connected to other important sentences receive higher scores.
Intuition. A sentence is important if it is similar to many other sentences in the document, especially to other important sentences. This captures centrality rather than just local features.
In practice, a TextRank style summarizer proceeds as follows, conceptually.
. Perform sentence segmentation and tokenisation.
. Build sentence vectors using TF IDF.
. Compute similarity between every pair of sentences to construct a weighted graph.
. Apply a random walk based ranking algorithm that iteratively updates sentence scores based on scores of neighbouring sentences.
. Sort sentences by final score and select the top ones, optionally enforcing diversity by penalising very similar sentences.
This approach is unsupervised. it does not require labelled summaries. It works well for generic summarization of news and blog articles and is a natural candidate for a teaching implementation.
Lecture 10 – Text Classification with Bag-of-Words and TF-IDF in NLP
Feature based extractive summarization and connection to text classification
Many extractive systems treat summarization as a sentence level classification or ranking task. The question becomes. should this sentence be in the summary or not
Features are often similar to those used in text classification.
. term frequency features, emphasising sentences that contain frequent topic words
. TF IDF based scores for important terms
. sentence position features. first sentences in news articles often carry key information
. similarity to the document title or headings
. presence of named entities, numbers or key phrases
A supervised model such as logistic regression, SVM or a neural classifier can be trained with labelled data where sentences are marked as summary worthy or not. This connects directly to Lecture nine, where classifiers operate over document representations. The difference is that here, the “documents” are individual sentences in context.
Abstractive summarization. conceptual view
Abstractive summarization is usually framed as a sequence to sequence problem similar to neural machine translation. The input is a long sequence (the document or several paragraphs) and the output is a shorter sequence (the summary).
Core ideas.
. an encoder network reads the document and builds contextual representations of each token
. a decoder network, often with attention and copy mechanisms, generates the summary token by token
. during training, the model is optimised to maximise the likelihood of reference summaries given the source documents
Attention lets the decoder focus on relevant parts of the input when generating each word. Copy or pointer mechanisms help the model reproduce key names, numbers and phrases from the source to avoid factual errors.
Challenges for abstractive summarization.
. long input sequences require efficient architectures or hierarchical encoders
. models may hallucinate details not grounded in the source
. evaluation with ROUGE may not fully capture summary quality, especially factual correctness
Despite these challenges, abstractive methods now power many commercial summarization tools and are a key research area in NLP.
Graph-based summarization with TextRank was introduced in this classic paper.
Evaluation of summaries. ROUGE intuition
Just as BLEU evaluates machine translation by comparing candidate outputs with reference translations, ROUGE (Recall Oriented Understudy for Gisting Evaluation) evaluates summaries by measuring overlap between n grams in the system generated summary and one or more human reference summaries.
There are several ROUGE variants.
. ROUGE N. measures recall of overlapping n grams. ROUGE one uses unigrams, ROUGE two uses bigrams.
. ROUGE L. uses longest common subsequence between system and reference summaries.
. ROUGE SU. considers skip bigrams and unigrams.
The core intuition is. good summaries should contain many of the same important phrases and word sequences as human written summaries. ROUGE emphasises recall, so longer summaries may score higher unless length control mechanisms are used.
Limitations.
. ROUGE does not account for paraphrases that use different wording.
. It is sensitive to tokenisation and morphological variation.
. High ROUGE does not guarantee factual correctness or coherence.
Therefore, while ROUGE is useful for quick automatic comparison of systems, it is still important to complement it with human evaluation in serious applications.
Evaluation of summaries. ROUGE intuition
Just as BLEU evaluates machine translation by comparing candidate outputs with reference translations, ROUGE (Recall Oriented Understudy for Gisting Evaluation) evaluates summaries by measuring overlap between n grams in the system generated summary and one or more human reference summaries.
There are several ROUGE variants.
. ROUGE N. measures recall of overlapping n grams. ROUGE one uses unigrams, ROUGE two uses bigrams.
. ROUGE L. uses longest common subsequence between system and reference summaries.
. ROUGE SU. considers skip bigrams and unigrams.
The core intuition is. good summaries should contain many of the same important phrases and word sequences as human written summaries. ROUGE emphasises recall, so longer summaries may score higher unless length control mechanisms are used.
Limitations.
. ROUGE does not account for paraphrases that use different wording.
. It is sensitive to tokenisation and morphological variation.
. High ROUGE does not guarantee factual correctness or coherence.
Therefore, while ROUGE is useful for quick automatic comparison of systems, it is still important to complement it with human evaluation in serious applications.
Real examples
- A news app that shows two or three sentence summaries of breaking stories on the home screen, allowing users to tap through only the items they care about.
- A research platform that generates short summaries of new arXiv papers, helping students keep track of developments in their field.
- A law firm tool that reads lengthy contracts and produces a one page summary of obligations, renewal dates and unusual clauses.
- A customer support dashboard that summarises each ticket thread into a single paragraph before assigning it to an agent.
- A project management system that summarizes meeting transcripts into bullet point decisions and action items.
Step by step algorithm explanation. simple TextRank style extractive summarizer
Here is a high level algorithm that you can present in a box.
Step one. Input a document and perform sentence segmentation to obtain a list of sentences.
Step two. Preprocess each sentence. lowercase, remove stopwords and optionally lemmatize tokens.
Step three. Represent each sentence as a vector using TF IDF over all sentences in the document.
Step four. Construct a similarity matrix where each entry is the cosine similarity between two sentence vectors. For pairs with similarity above a threshold, create edges in a graph with weights equal to the similarity value.
Step five. Apply a ranking algorithm similar to PageRank. initialize each sentence score equally, then iteratively update each score based on the scores of neighbouring sentences and edge weights, until convergence.
Step six. Sort sentences by final score in descending order.
Step seven. Select the top k sentences that fit within the desired summary length, optionally ensuring diversity by avoiding sentences that are very similar to ones already chosen.
Step eight. Arrange the selected sentences in their original document order to form the extractive summary.
This algorithm shows how graph based centrality can be used to identify the most representative sentences of a document without any labelled data.
Code example. minimal extractive summarizer in Python
The following example demonstrates a very simple extractive summarizer using TF IDF and cosine similarity. It is not a full TextRank implementation but captures the basic idea of scoring sentences.
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
import numpy as np
import nltk
nltk.download("punkt")
def simple_extractive_summary(text, max_sentences=3):
# Sentence segmentation
sentences = nltk.sent_tokenize(text)
if len(sentences) <= max_sentences:
return text
# TF-IDF sentence vectors
vectorizer = TfidfVectorizer(stop_words="english")
tfidf = vectorizer.fit_transform(sentences)
# Similarity matrix
sim_matrix = cosine_similarity(tfidf)
# Simple centrality score: sum of similarities to other sentences
scores = sim_matrix.sum(axis=1)
# Indices of top scoring sentences
top_indices = np.argsort(scores)[::-1][:max_sentences]
top_indices = sorted(top_indices) # keep original order
# Build summary
summary_sentences = [sentences[i] for i in top_indices]
return " ".join(summary_sentences)
if __name__ == "__main__":
doc = """
Text summarization is an important task in natural language processing.
It aims to produce a concise summary of a longer document while preserving key information.
Extractive methods select important sentences directly from the source text.
Abstractive methods generate new sentences that paraphrase the main ideas.
Summarization is widely used for news, research papers and legal documents.
"""
print(simple_extractive_summary(doc, max_sentences=2))Summary
Text summarization in NLP provides essential tools for coping with information overload by condensing long documents into concise summaries. Extractive methods, including graph based approaches like TextRank, select important sentences from the original text, while abstractive methods use neural sequence models to generate new, paraphrased summaries. Both paradigms have strengths and weaknesses, and practical systems often combine them.
Evaluation with ROUGE offers a convenient way to compare system summaries with human references, although human judgment remains important for assessing coherence and factual accuracy. From news apps and research platforms to legal and enterprise tools, summarization has become a core component of modern information systems.
Next. Natural Language Processing Exam Questions – 100 MCQs, 30 Short and 15 Long
People also ask:
Text summarization in NLP is the automatic generation of a shorter version of a document that preserves its main ideas and important information. Summaries can be single document or multi document and are used to help readers understand content quickly.
Extractive summarization selects existing sentences or phrases from the original document and concatenates them to form a summary. Abstractive summarization generates new sentences that paraphrase and compress the content, similar to how humans write summaries.
Graph based methods represent sentences as nodes in a graph and connect them based on similarity. A ranking algorithm similar to PageRank assigns higher scores to sentences that are strongly connected to other important sentences. The top ranked sentences are then chosen as the summary.
ROUGE compares system generated summaries with one or more human reference summaries by measuring overlap of n grams, subsequences or skip bigrams. Higher ROUGE scores indicate that the system summary shares more content with the references, although ROUGE does not fully capture fluency or factual accuracy.
Practical applications include summarizing news articles for feeds, generating short overviews of research papers, condensing legal and regulatory documents, summarizing customer support tickets and producing meeting minutes from transcripts. Summarization helps professionals and end users process information more efficiently.