A detailed guide to the perceptron learning model covering architecture, learning rule, linear separability, limitations, and ANN design concepts.
The perceptron learning model represents a foundational milestone in the development of artificial neural networks. It was the first computational model capable of learning from data by adjusting internal parameters, introducing the core idea that machines can learn decision rules rather than follow fixed instructions.
Although simple by modern standards, the perceptron is critically important for understanding how neural networks are designed, how learning occurs, and why deeper architectures were eventually required. This lecture explores the perceptron in depth, focusing on its architecture, learning mechanism, problem-solving capability, and limitations, with an emphasis on designing simple ANN systems.
Historical Background of the Perceptron
The perceptron was introduced in the late 1950s as an attempt to model intelligent behavior using biologically inspired computation. At the time, it generated significant excitement because it demonstrated that a machine could learn to classify patterns through experience.
However, early expectations were too ambitious. While the perceptron could learn simple tasks, its limitations eventually became clear. Understanding this historical context helps students appreciate both the strengths and weaknesses of early neural models and the motivation behind multi-layer networks.
What Is the Perceptron?
The perceptron is a single-layer, feedforward neural network used primarily for binary classification. It maps input features to an output decision by learning a linear decision boundary.
Key characteristics of the perceptron include:
- Supervised learning
- Weight-based decision making
- Threshold-based output
- Linear classification capability
Unlike modern deep networks, the perceptron contains only one layer of trainable weights, which fundamentally restricts what it can learn.
Semantic context: perceptron model, simple ANN, linear classifier
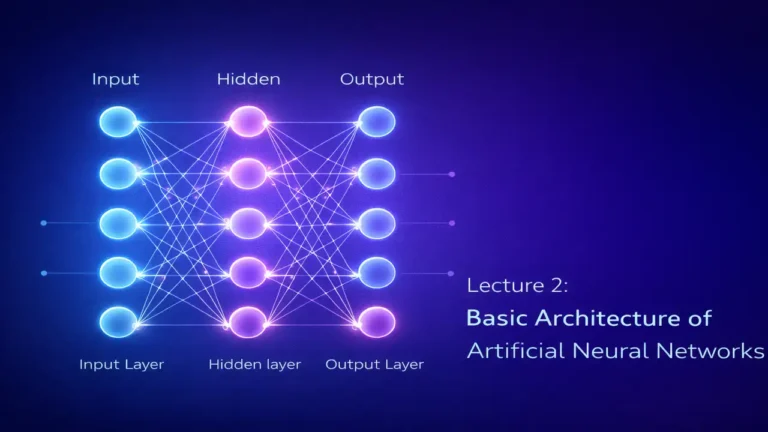
Lecture 2 : Basic Architecture of Artificial Neural Networks
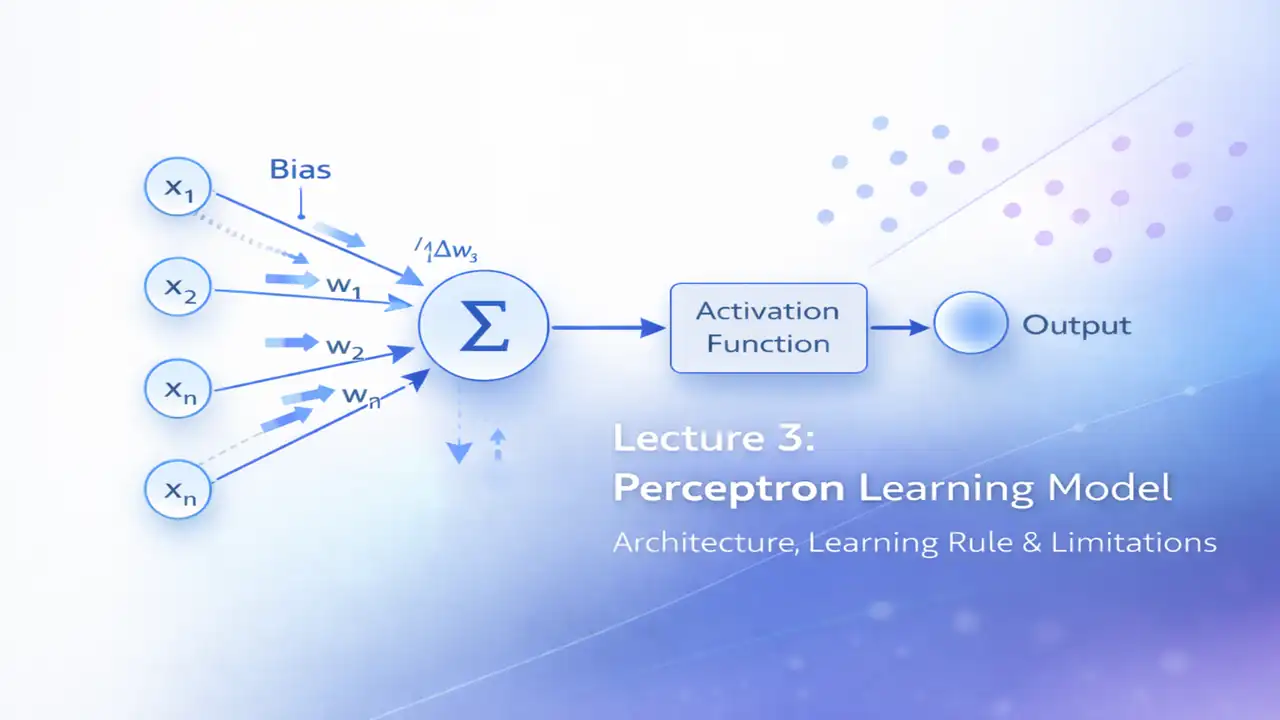
Perceptron Architecture in Detail
The architecture of a perceptron closely resembles the artificial neuron discussed in the previous lecture, but with a specific learning objective.
Core Components of the Perceptron
1. Input Layer
The input layer consists of numerical features representing data points. Each input corresponds to a measurable attribute of the problem.
2. Weights
Each input is associated with a weight that determines its influence on the output decision. Weights are the parameters learned during training.
3. Bias
The bias term shifts the decision boundary, allowing the perceptron to model more flexible decision regions.
4. Summation Unit
All weighted inputs and bias are combined to form a single scalar value.
5. Activation Function
Traditionally, the perceptron uses a step or threshold activation function that produces a binary output.
6. Output
The output represents the predicted class, typically 0 or 1.
Semantic context: perceptron architecture, ANN components
Conceptual Mathematical Interpretation
Although the perceptron is defined mathematically, students should first understand its conceptual behavior.
The perceptron:
- Computes a weighted sum of inputs
- Compares the result to a threshold
- Assigns a class label based on this comparison
Geometrically, this corresponds to drawing a straight line (or hyperplane) that separates two classes of data. Learning means adjusting this line so that it correctly divides the data.
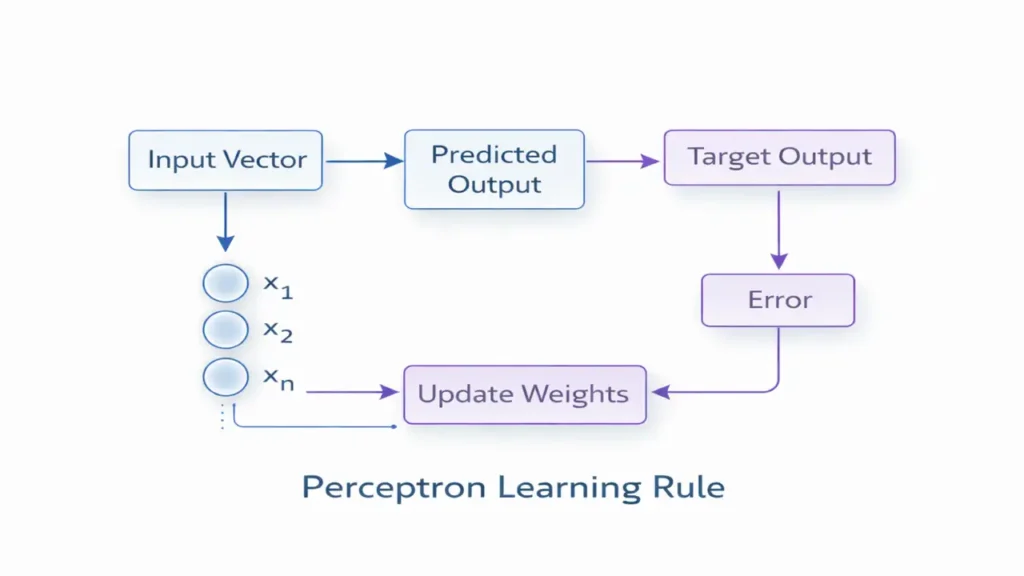
The Perceptron Learning Rule
The learning rule defines how the perceptron modifies its weights during training. This rule is the heart of the perceptron model.
Learning Process Overview
- An input vector is presented
- The perceptron computes an output
- The output is compared to the desired target
- If the prediction is incorrect, weights are updated
- The process repeats for multiple training examples
This learning process continues until:
- All training samples are correctly classified, or
- A predefined number of iterations is reached
Key Properties of the Learning Rule
- Learning occurs only when errors happen
- Correct predictions do not change weights
- Learning is incremental and data-driven
This rule ensures that the perceptron gradually improves its decision boundary through experience.
Semantic context: perceptron learning rule, supervised learning
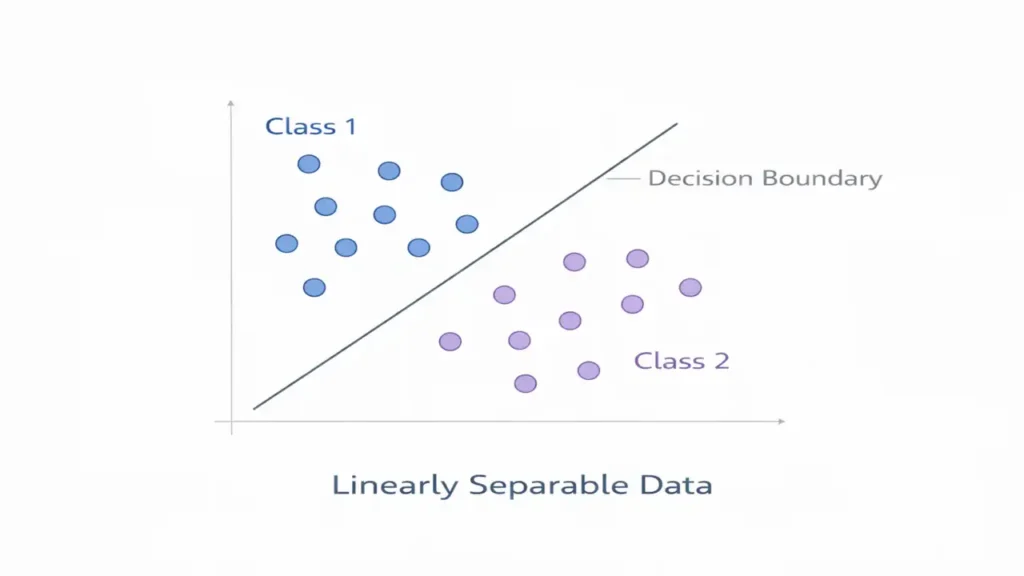
Understanding Linearly Separable Problems
A central concept in perceptron theory is linear separability.
What Does Linearly Separable Mean?
A dataset is linearly separable if a straight line (in two dimensions) or a hyperplane (in higher dimensions) can completely separate data points of different classes.
Examples of Linearly Separable Problems
- AND logic gate
- OR logic gate
- Simple two-class datasets with clear boundaries
In such cases, the perceptron learning algorithm is guaranteed to find a solution.
Semantic context: linear separability, decision boundary
Limitations of the Perceptron
Despite its historical importance, the perceptron has fundamental limitations that restrict its usefulness.
Major Limitations Explained
1. Inability to Solve Non-Linear Problems
The perceptron cannot solve problems where data cannot be separated by a straight line.
2. XOR Problem
The XOR logic function is the most famous example of a non-linearly separable problem that a perceptron cannot learn.
3. Single-Layer Restriction
With only one layer of trainable weights, the perceptron lacks representational power.
4. Poor Performance on Complex Data
Real-world problems often involve overlapping classes and non-linear patterns, which exceed the perceptron’s capability.
These limitations directly motivated the development of multi-layer perceptrons and backpropagation algorithms.
Semantic context: perceptron limitations, XOR problem
Designing Simple ANN Models Using Perceptron Concepts
Despite its limitations, the perceptron is extremely valuable for learning ANN design principles.
Using perceptron concepts, students learn how to:
- Select input features
- Initialize weights
- Choose activation functions
- Define decision boundaries
- Evaluate classification performance
These skills transfer directly to more advanced neural network architectures.
Frequently Asked Questions
Yes, it can update weights incrementally as new data arrives.
As a practical model, yes. As a learning concept, absolutely not.
Multi-layer perceptrons combined with backpropagation solved many of its limitations.
Conclusion
The perceptron learning model laid the foundation for modern neural networks. While simple, it introduced the revolutionary idea that machines can learn from data by adjusting internal parameters. Understanding the perceptron provides essential insight into how artificial neural networks evolved and why deep learning architectures were developed.
This lecture prepares students to explore more powerful models such as ADALINE, multi-layer perceptrons, and deep neural networks.
Next Lecture – ADALINE & Minimum Error Learning