
Introduction
Transformers are the most powerful and game-changing architecture in modern deep learning. From BERT and GPT-4 to Stable Diffusion and Gemini nearly every cutting-edge AI model today is built using the Transformer architecture. Before Transformers, RNNs, LSTMs, and GRUs dominated sequence modeling. But these older architectures suffered from sequential processing, long-range dependency issues, and slow training times.
Transformers solved all of this using self-attention, parallel processing, and multi-head attention, leading to massive improvements in accuracy, scalability, and speed. In this lecture, we explore the entire architecture of Transformers from QKV vectors to positional encoding, encoder–decoder design, and real-world applications.
This is one of the most important lectures in your Deep Learning series.
Why Transformers Were Needed
Before Transformers, deep learning models used RNN-based sequence processing:
- They processed tokens one at a time
- Unable to parallelize computations
- Suffered from vanishing gradients
- Struggled with long sentences
- Lost context across distant tokens
Even attention added to RNNs improved things, but still — sequential processing limited performance.
Transformers changed everything by:
Removing RNNs entirely
Introducing Self-Attention
Allowing complete parallelism
Handling long sequences smoothly
Scaling up to billions of parameters
This shift enabled modern AI as we know it.
What Are Transformers?
A Transformer is a deep learning architecture based entirely on Attention Mechanisms.
It processes sequences in parallel instead of step-by-step.
A Transformer consists of:
- Encoder (for understanding input)
- Decoder (for generating output)
- Self-Attention layers
- Multi-Head Attention
- Feed-Forward Networks
- Positional Encoding
Its strength comes from its ability to:
Compare every token with every other token
Learn relationships globally
Focus on relevant words automatically
Scale on GPUs with parallel training
Transformers can learn extremely complex patterns, making them ideal for:
- NLP
- Vision
- Audio
- Multimodal AI
- Generative models
Core Components of the Transformer Architecture
Let’s break down each major building block.
Input Embeddings
Every token is turned into a dense vector.
For example:
“Transformers are powerful.”
Each word is mapped to a vector like:[0.12, 0.54, -0.33, ...]
These embeddings capture:
- Semantic meaning
- Contextual relationships
- Word similarity
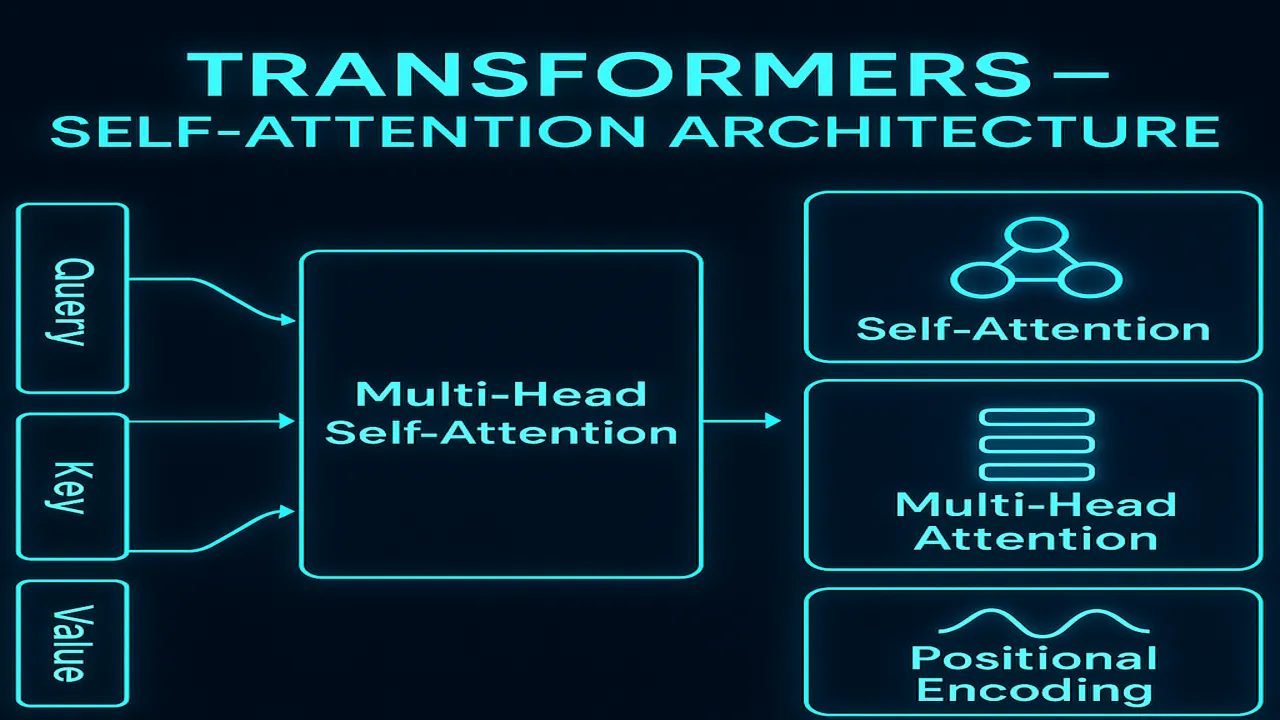
Positional Encoding
Transformers do not have any sense of order (unlike RNNs).
To teach them order, we add positional encodings.
These are sinusoidal or learned vectors added to the embeddings:
Embedding + Positional EncodingThis enables the model to know:
- First token
- Next token
- Distances between tokens
- Relative positions
This is crucial for translation, summarization, and reasoning.
Self-Attention Mechanism (QKV)
This is the heart of the Transformer.
Each token generates three vectors:
- Q → Query
- K → Key
- V → Value
These determine:
- What the token is looking for (Q)
- What information it contains (K)
- What information to pass (V)
Self-Attention computes:
Attention = softmax(QKᵀ / √d_k) VThis allows tokens to attend to each other.
Example:
Sentence → “The cat sat on the mat.”
The word “cat” will attend strongly to:
- “The”
- “sat”
- “mat”
This produces context-aware embeddings.
Multi-Head Attention
Instead of using one attention pattern, Transformers use multiple:
Head 1 → learns syntax
Head 2 → learns semantics
Head 3 → learns entity relationships
Head 4 → learns long-range dependenciesMultiple heads allow the model to understand language from different perspectives simultaneously.
Feed-Forward Neural Network (FFN)
After attention, the model applies a two-layer feed-forward network.
This improves:
- Representation learning
- Abstraction
- Feature transformation
FFN is applied independently to each position.
Residual Connections + Layer Normalization
Transformers train deep models easily because they use:
- Skip connections
- Layer normalization
These help gradients flow smoothly.
Transformer Encoder Architecture
Each Encoder block contains:
- Self-Attention layer
- Add & Norm
- Feed-Forward Network
- Add & Norm
Encoders analyze input sequence holistically.
Applications:
- BERT
- Sentence Embeddings
- Feature extraction
Transformer Decoder Architecture
The decoder adds two more components:
- Masked Self-Attention
- Encoder–Decoder Attention
Masked self-attention prevents the model from seeing future tokens during generation.
Encoder–decoder attention helps it focus on relevant parts of the input.
Applications:
- GPT
- Translation
- Summarization
- Text generation
Attention is All You Need Original Transformer Paper
How Transformers Process a Sequence (Step-by-Step)
Let’s see the flow:
Step 1 – Convert input tokens to embeddings
Words → vectors
Step 2 – Add positional encoding
Gives the model position awareness.
Step 3 – Pass through Encoder Self-Attention
Each token attends to all others.
Step 4 – Feed-Forward Network
Enhances representation.
Step 5 – Decoder Self-Attention
Decoder attends to previous generated tokens.
Step 6 – Encoder–Decoder Attention
Decoder focuses on relevant words from the Encoder.
Step 7 – Output Layer
Predicts next token.
This continues until the model generates an end token.
Advantages of Transformers
Transformers outperform previous models because they:
Train in parallel
Huge speed improvement.
Capture global relationships
Better long-range understanding.
Scale to large datasets
Billions of parameters are possible.
Show state-of-the-art performance
Every major AI task now uses Transformers.
Enable multimodal AI
Text, image, video, audio all unified.
Applications of Transformers
Transformers power:
NLP
- BERT
- GPT-3, GPT-4
- T5
- LLaMA
- Mistral
Vision
- Vision Transformers
- Image Captioning
- Diffusion Models
Speech
- Whisper
- Wav2Vec
Generative AI
- Chatbots
- Text-to-image models
- Video Generation models
Industry
- Medical diagnosis
- Autonomous driving
- Finance modeling
- Robotics
Modern Variants of Transformers
BERT
Bidirectional encoder model.
GPT
Decoder-only autoregressive model.
ViT
Vision Transformer for images.
T5
Unified text-to-text transformer.
LLaMA & Mistral
Lightweight, fast, powerful models.
Why Transformers Changed AI Forever
Transformers enabled:
Larger models
Faster training
Better reasoning
Cross-modal understanding
Natural language fluency
Contextual memory over long text
They are the foundation behind every major breakthrough from 2017 to now.
People also ask:
Because they process sequences in parallel, capture long-range context, and scale better.
Self-Attention allows each token to analyze every other token in the sequence.
Because they do not have sequence order naturally.
To learn multiple types of relationships simultaneously.
Yes they dominate vision, audio, speech, and generative AI.


