Clear, up-to-date guide to 18 types of AI agents and LLM architectures what they are, when to use them, stacks, pitfalls, and FAQs.
What is an AI Agent?
An AI agent is a system that (1) understands inputs, (2) reasons about goals, constraints, and tools, and (3) acts by calling APIs, controlling software/robots, or producing outputs (text, code, images, speech). Agents often chain several model types to cover these capabilities.
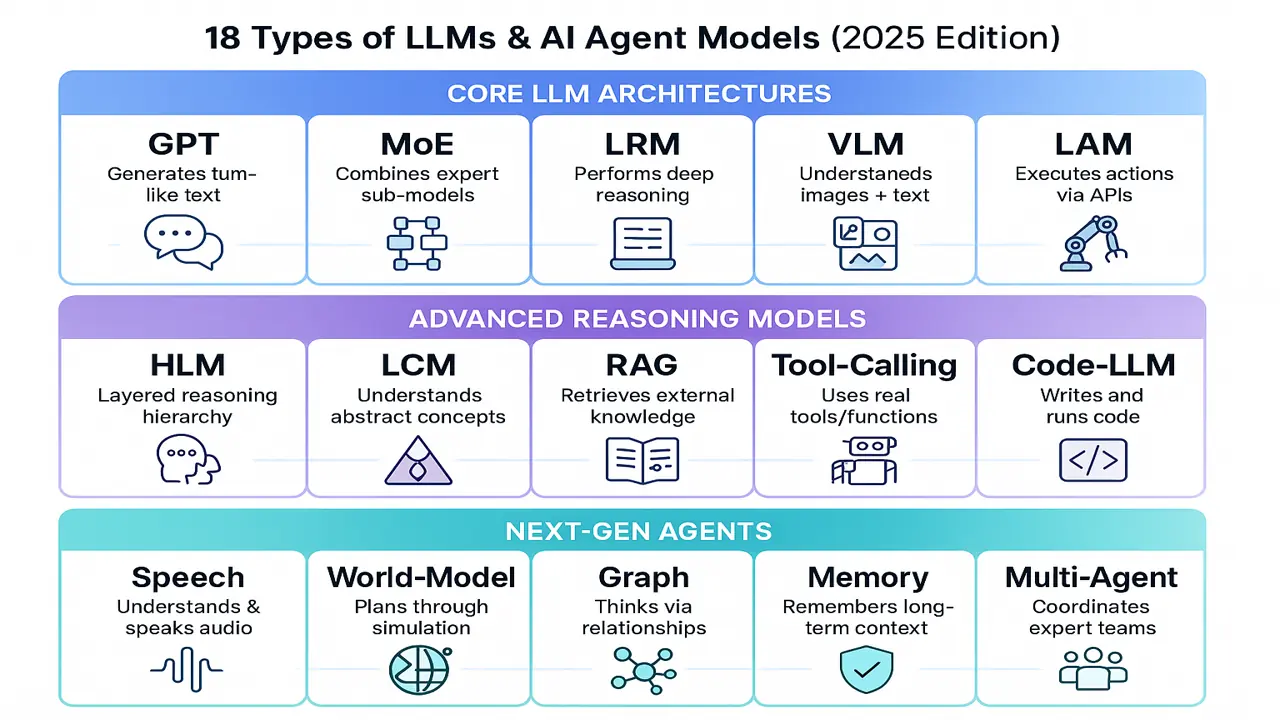
Category A Core LLM Architectures (Foundation Layer)
1) GPT Generative Pretrained Transformer
- What it is: Large transformer trained on broad text and code.
- Best for: Conversation, writing, summarization, code drafting, general reasoning.
- Watch-outs: Hallucinations without grounding; may need guardrails + RAG.
2) MoE Mixture of Experts
- What it is: Sparse model routing tokens to a few “expert” sub-networks.
- Best for: High performance at lower inference cost on large workloads.
- Watch-outs: Load balancing, expert collapse, and routing stability.
3) LRM Large Reasoning Model
- What it is: LLM tuned for stepwise logical reasoning/planning.
- Best for: Math, proofs, tool-augmented multi-step tasks, strategy.
- Watch-outs: Slower; benefits from verifiers, code execution, or self-consistency.
4) VLM Vision-Language Model
- What it is: Joint vision + text understanding.
- Best for: Image Q&A, captioning, document understanding, UI analysis.
- Watch-outs: Requires careful prompt images; privacy for screenshots/docs.
5) SLM Small Language Model
- What it is: Compact models (1–8B) for on-device or low-latency use.
- Best for: Edge/IoT, privacy-sensitive apps, offline assistants.
- Watch-outs: Limited context/knowledge pair with RAG or server LLM.
6) LAM Large Action Model
- What it is: Language model optimized to use tools and execute tasks.
- Best for: Booking, reporting, system automation, robotic skills via APIs.
- Watch-outs: Tool schemas, auth, auditing, and reversible actions.
Category B Advanced Reasoning & Multimodal (Capability Layer)
7) HLM Hierarchical Language Model
- What it is: Layered control (planner → sub-tasks → skills).
- Best for: Long projects, workflows with dependencies.
- Watch-outs: State explosion; needs memory + progress tracking.
8) LCM Large Concept Model
- What it is: Concept-centric understanding beyond surface tokens.
- Best for: Thematic search, ontology tasks, semantic clustering.
- Watch-outs: Evaluation is tricky; still emerging in practice.
9) RAG-LLM Retriever-Augmented Generation
- What it is: LLM grounded by document/vector retrieval with citations.
- Best for: Enterprise Q&A, policy assistants, customer support, research.
- Watch-outs: Index freshness, chunking, evaluation on groundedness.
10) Tool-Calling / Function-Calling LLM
- What it is: Structured arguments to call APIs, DBs, code, spreadsheets.
- Best for: Real workflows (CRM, ERP, analytics, emails, calendar).
- Watch-outs: Schema drift, error handling, retries, rate limits.
11) VLA Vision-Language-Action
- What it is: Perceive (vision), reason (language), act (mouse/keyboard/robot).
- Best for: Computer control, RPA 2.0, robotics, AR assistance.
- Watch-outs: Safety, grounding, and reproducibility of UI states.
12) Code-LLM Program Synthesis/Repair
- What it is: Models specialized for code, tests, and program-of-thought.
- Best for: Agents that write+run code, ETL, data science, infra automation.
- Watch-outs: Sandbox execution, secrets handling, dependency security.
AI Forecasts Stock Trends with Transformers 2025 Market Prediction Revolution
Category C Next-Gen Agent Systems (System Layer)
13) Speech/Audio LLM
- What it is: End-to-end speech understanding + TTS with low latency.
- Best for: Voice agents, call-center copilots, meeting summarization.
- Watch-outs: Accents/noise robustness, consent/recording policies.
14) World-Model / Simulation-Guided Agent
- What it is: Learns a predictive model of the environment to plan ahead.
- Best for: Robotics, logistics, games, what-if planning.
- Watch-outs: Sim-to-real gap; requires careful evaluation.
15) Graph/KG-Augmented LLM
- What it is: Combines LLMs with knowledge graphs or graph reasoning.
- Best for: Compliance, biomedical/fin discovery, supply chain.
- Watch-outs: Graph upkeep; entity alignment between text and graph.
16) Memory-Augmented / Long-Horizon Agent
- What it is: Vector + episodic memory, notes, calendars; learns user prefs.
- Best for: Personal/productivity agents, long projects and research.
- Watch-outs: Forgetting policies, privacy, PII retention limits.
17) Safety/Guardrail Model (Moderator/Constitutional)
- What it is: Filters prompts/outputs, redacts PII, enforces policy.
- Best for: Regulated industries, kid-safe experiences, brand protection.
- Watch-outs: Over-blocking vs under-blocking; appeals and logging.
18) Multi-Agent Orchestrator
- What it is: A planner/dispatcher that coordinates specialist agents.
- Best for: Complex pipelines R&D, growth marketing, analytics, LLM ops.
- Watch-outs: Cost control, loop detection, task handoff quality.
Choosing the Right Stack (Practical Recipes)
Knowledge assistant (enterprise docs):
RAG-LLM (retrieval) + GPT/LRM (generation) + Guardrail + Memory (user history).
Data analyst copilot:
Tool-Calling (SQL/BI) + Code-LLM (Python/R) + GPT (narratives) + Guardrail.
Computer-use agent (UI automation):
VLM (screen understanding) + VLA (mouse/keyboard) + LAM (tools) + Safety.
Voice service agent:
Speech LLM (ASR/TTS) + RAG-LLM (answers) + Tool-Calling (tickets/CRM) + Memory.
Robotics/operations:
VLA (control) + World-Model (planning) + Graph/KG (constraints) + Guardrail.
valuation & Safety Checklist
- Groundedness: Use RAG with citations for factual tasks.
- Tool safety: Typed schemas, dry-run mode, audit logs, and reversible actions.
- Cost/latency: Mix SLM on device + server LLM; cache retrievals; batch tools.
- Memory policy: TTLs, user export/delete, encrypt at rest, minimize PII.
- Multi-agent control: Timeouts, deduplication, arbitration, human-in-the-loop.
- Observability: Traces, prompts, tool calls, and dataset versioning.
Common Errors (and Fixes)
- Hallucinations: Add RAG, verifiers, and confidence scoring.
- Brittle tool calls: Validate JSON, retries with backoff, fallback handlers.
- Long tasks stall: Use HLM for planning + Memory for progress + checkpoints.
- Poor UI reliability: For VLA, stabilize with template locators and state checks.
- Cost spikes: MoE or SLM for easy turns; stream responses; cache embeddings.
Summary
Building effective AI agents is about composing the right model types. Use Core LLMs for language capability, add Advanced layers for grounding, code, and action, and wrap everything in Next-Gen system components (memory, safety, orchestration). With solid evaluation and guardrails, you can deploy reliable, cost-aware agents that ship real value.
The approach followed at E Lectures reflects both academic depth and easy-to-understand explanations.
People also ask:
An LLM generates/understands content; an agent wraps the LLM with tools, memory, policies, and goals so it can plan and act in the world.
Use RAG when knowledge changes often or must be cited. Use fine-tuning for style, domain behavior, or private patterns that don’t frequently change often you’ll do both.
MoE reduces compute for large models; SLMs run cheaply on device; caching + RAG cut prompt sizes and repeated calls.
Use approval gates, dry-runs, scopes/quotas, and allow-lists. Log every call; add a guardrail model to check intent and arguments before execution.
RAG-LLM (grounded answers) + Tool-Calling (limited) + Guardrail (policy/PII) + Observability (traces) + Optional Memory (per-user context).
A VLM understands images + text; a VLA also acts (mouse/keyboard/robot). It’s perception + reasoning + action in one loop.
No. Use HLM when tasks span many steps or days. For short tasks, a single planner (LRM/GPT) with tools is enough.
Track task success, groundedness, tool error rates, cost/latency, and user satisfaction. Use gold tasks and A/B runs with the same tools/data.
![Top 10 Ways AI Automation for Business Is Transforming the Future [2025 Edition]](https://electuresai.com/wp-content/uploads/2025/12/A_digital_illustration_serves_as_the_header_image__featured_converted-768x432.webp)