Why do CNNs use pooling layers?
Lecture 7 – Pooling Layers in Convolutional Neural Networks
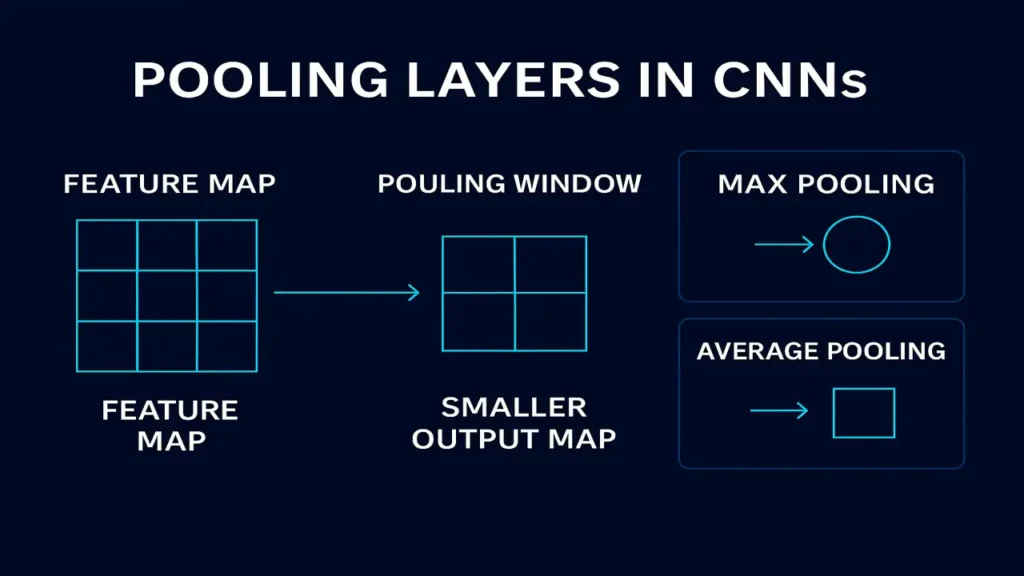
Pooling layers are a core component of Convolutional Neural Networks (CNNs). After convolutions extract features, pooling layers compress and refine those features, making the network faster, more stable, and more robust. Without pooling, CNNs would be slow, memory-heavy, and overly sensitive to tiny changes in the input.
This lecture explains what pooling layers are, why they are essential, how max pooling, average pooling, and global pooling work, and how pooling contributes to translation invariance.
What Are Pooling Layers?
Pooling is a downsampling operation applied to feature maps in CNNs.
Its goal is simple:
Reduce spatial dimensions while keeping the most important information
If a convolution layer outputs a 32×32 feature map, pooling may reduce it to 16×16, 8×8, or even 1×1.
Why is this reduction useful?
Faster computation
Fewer parameters → less overfitting
More robust to noise
Translation invariance (object shifts don’t break detection)
Pooling works by applying a small window (like 2×2 or 3×3) and summarizing values within that window.
Types of Pooling Layers
Max Pooling (Most Common)
Max pooling selects the maximum value inside each pooling window.
Example with a 2×2 window:
| 4 | 2 |
| 1 | 8 |
Max pooling output: 8
Why it works:
- Keeps the strongest activation
- Captures dominant features
- Preferred in modern CNNs like VGGNet, ResNet, MobileNet
Average Pooling
Average pooling returns the mean value in each window.
Same window:
| 4 | 2 |
| 1 | 8 |
Average pooling output: (4+2+1+8)/4 = 3.75
Used when:
- You want smoother, less aggressive feature reduction
- Often seen in early CNN architectures like LeNet-5
Global Pooling
Global pooling reduces an entire feature map to one value.
Example:
Feature map 8×8 → becomes 1×1.
Types:
- Global Max Pooling
- Global Average Pooling (GAP)
Used in:
- MobileNet
- ResNet (for classification head)
- Modern architectures replacing fully connected layers
Benefits:
Prevents overfitting
Reduces parameters dramatically
Great for mobile and embedded devices
Hyperparameters in Pooling Layers
Pooling layers use three main hyperparameters:
Pool Size
- Usually 2×2 or 3×3
Stride
- How far the window moves
- Common value: 2
Padding
- Usually no padding (valid pooling)
- Keeps pooling aggressive
How Pooling Helps CNNs Learn Better
Pooling improves learning in four ways:
Reduces Computation
Smaller feature maps → fewer operations → faster training.
Controls Overfitting
Removes excess details and noise.
Deep models generalize better.
Provides Translation Invariance
If an object moves slightly in an image, pooling ensures its features still match.
Strengthens Dominant Features
Max pooling highlights the strongest edges, textures, and shapes.
Example (Step-by-Step Pooling Operation)
Consider a feature map:
| 2 | 5 | 1 | 3 |
| 6 | 8 | 2 | 1 |
| 4 | 7 | 9 | 2 |
| 1 | 3 | 5 | 6 |
Apply 2×2 Max Pooling, stride 2.
Window 1:
| 2 | 5 |
| 6 | 8 | → Max = 8
Window 2:
| 1 | 3 |
| 2 | 1 | → Max = 3
Window 3:
| 4 | 7 |
| 1 | 3 | → Max = 7
Window 4:
| 9 | 2 |
| 5 | 6 | → Max = 9
Final pooled output:
| 8 | 3 |
| 7 | 9 |
This dramatically shrinks information while keeping the strongest signals.
Pooling vs Convolution: Key Differences
| Convolution | Pooling |
|---|---|
| Learns filters | No learning; uses simple ops |
| Extracts features | Downsamples features |
| Can detect patterns | Makes representations compact |
| Produces many maps | Reduces map sizes |
Pooling is not a replacement it complements convolution.
When NOT to Use Pooling?
In some architectures like Vision Transformers (ViT) or certain ResNet variants:
Pooling is removed
Replaced by strided convolutions
Or patch embeddings
Used when:
- You don’t want information loss
- You want smoother gradients
Summary
Pooling layers reduce spatial size, remove noise, and keep important features.
They make CNNs faster, more robust, and more accurate by summarizing information into smaller, meaningful maps.
People also ask:
To reduce dimensions, prevent overfitting, and provide translation invariance.
Max pooling is typically used because it captures the strongest features.
Not usually it improves generalization and prevents noise from affecting predictions.
Global pooling reduces entire maps to one value; normal pooling uses small windows.
Yes, using strided convolutions, but pooling is still popular due to simplicity and robustness.