What are Seq2Seq models used for?
Lecture 13 – Sequence-to-Sequence Models with Attention: Architecture, Workflow & Real-World Applications
Introduction
Sequence-to-Sequence models transformed deep learning by enabling neural networks to understand one sequence and generate another. Whether it is language translation, text summarization, speech recognition, dialogue systems, caption generation, or code completion Seq2Seq models form the backbone of most modern sequence-based AI applications.
In this lecture, we explore how Seq2Seq models work, how the encoder–decoder architecture processes sequences, the limitations of fixed context vectors, and how attention mechanisms solved these limitations. By the end, you will understand not only the architecture but also why attention changed the game and how modern systems still rely on this concept in more advanced forms like Transformers.
What Are Sequence-to-Sequence Models?
Sequence-to-Sequence (Seq2Seq) models are deep learning architectures designed to convert one sequence into another. For example:
- Input:
"I love apples" - Output:
"Ich liebe Äpfel" - Input: audio waveform
- Output: text transcript
- Input: long article
- Output: summary paragraph
The key idea is that the model does not classify or predict a single value it generates a sequence, token by token.
Traditional feed-forward networks cannot handle variable length sequences. Seq2Seq models solved this by introducing Encoder–Decoder architectures, often using RNNs, GRUs, or LSTMs.
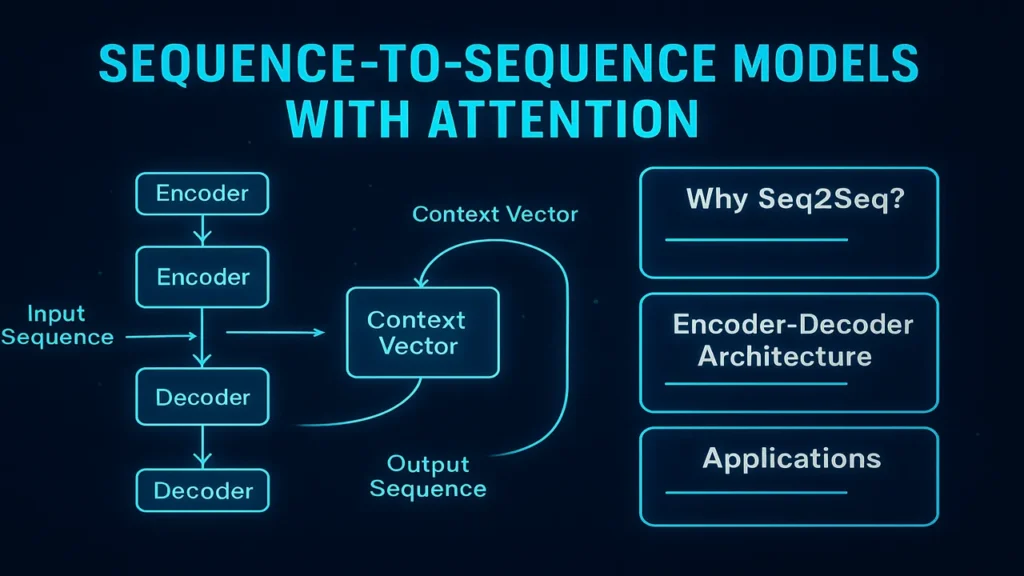
Encoder–Decoder Architecture
The architecture consists of two major parts:
Encoder
The encoder reads the input sequence one token at a time and encodes it into a hidden state representation.
If the input is:["I", "love", "apples"],
each token passes through RNN/GRU/LSTM layers and produces a hidden state.
The final hidden state is called the context vector a compressed summary of the entire input sequence.
Decoder
The decoder generates output tokens using:
- The context vector (from the encoder)
- Its own previous hidden states
- Previously generated tokens
For translation, the decoder might generate:["Ich", "liebe", "Äpfel"]
Token by token, the output grows until the model predicts an <EOS> (end-of-sequence) token.
Limitation of Basic Seq2Seq Models: The Bottleneck Problem
The biggest weakness in early Seq2Seq models was the fixed-size context vector.
No matter how long the input sentence is the entire meaning has to be compressed into a single vector.
This causes problems:
- Long sentences lose information
- Context becomes blurry
- Translations degrade
- The model forgets early parts of the input
This is called the bottleneck problem.
And that’s where attention mechanisms changed everything.
Attention Mechanism: The Breakthrough
Attention allows the model to “look back” at the entire input sequence while generating each output token.
Instead of relying on one context vector, the model:
Assigns weights to each encoder hidden state
Calculates relevance of each input token
Generates context dynamically for each output step
This means:
- When generating “Äpfel”, the model pays attention to “apples”
- When generating “liebe”, it attends to “love”
Attention made translations clearer, summaries cleaner, and long-sequence modeling dramatically better.
How Attention Works (Step-by-Step)
Let’s break it down:
Step 1 – Encoder produces hidden states
For each input token:
h1, h2, h3 … hnThese store meaning at each timestep.
Step 2 – Decoder requests information
At each decoding step, the decoder takes its hidden state:
s_tAnd asks: “Which encoder states are relevant right now?”
Step 3 – Alignment Scores
The decoder compares s_t with each encoder hidden state h_i.
This produces alignment scores (also called relevance scores).
Step 4 – Softmax Converts Scores into Attention Weights
Softmax ensures weights add up to 1:
α1 + α2 + α3 ... + αn = 1
These weights represent which words to pay attention to.
Step 5 – Weighted Sum = Context Vector
A new context vector is created for that specific token:
c_t = Σ (α_i * h_i)This dynamic context vector is fed into the decoder.
Step 6 – Decoder generates output token
The decoder now has exactly the information it needs.
Types of Attention Mechanisms
Bahdanau (Additive) Attention
Introduced by Bahdanau et al. (2014), this method:
- Computes scores using a feed-forward network
- Works well with LSTMs and GRUs
- Known for high accuracy
Luong (Multiplicative) Attention
Introduced by Luong et al. (2015):
- Uses dot-products
- Faster and more efficient
- Works well with large models
Training Process of Seq2Seq Models
Teacher Forcing
To train faster, the model is given the correct previous token instead of its own predicted token 50–70% of the time.
This stabilizes training.
Loss Function
Most commonly, Cross-Entropy Loss is used.
Optimization
Optimizers like Adam or RMSProp update weights over time.
Real-World Applications of Seq2Seq Models
Seq2Seq models are everywhere:
Machine Translation (Google Translate)
Chatbots
Speech-to-Text
Text Summarization
Image Captioning
Question Answering
Code Completion
Medical report generation
Even though Transformers are now dominant, Seq2Seq + Attention was the foundation that made them possible.
Advanced Example: Step-by-Step Translation Process
Let’s translate:
Input: “She is reading a book.”
Output: “Sie liest ein Buch.”
Encoder creates states for each word.
Decoder generates: “Sie”
→ pays attention mainly to “She”.
Decoder generates: “liest”
→ attends to “is reading”.
Decoder generates: “ein Buch”
→ attends to “a book”.
This dynamic attention results in fluent translations.
Why Seq2Seq is Still Important in Modern Deep Learning
Even though Transformers replaced RNN-based Seq2Seq, the architecture still matters because:
- It teaches core ideas of sequence modeling
- Attention was invented here
- The encoder-decoder idea is reused in Transformers
- Modern NLP still uses hybrid approaches combining Seq2Seq principles
Understanding Seq2Seq means understanding the foundation of Transformer models.
People also ask:
They convert one sequence into another, such as translation, summarization, and dialogue generation.
Because the fixed context vector cannot hold all information, creating a bottleneck.
The decoder generates output tokens using the context vector, previous tokens, and its hidden states.
Attention lets the model focus on relevant parts of the input at each output step.
Yes, but Seq2Seq concepts remain the foundation of modern architectures.