What is question answering in NLP?
Lecture 14 – Question answering in Natural Language Processing
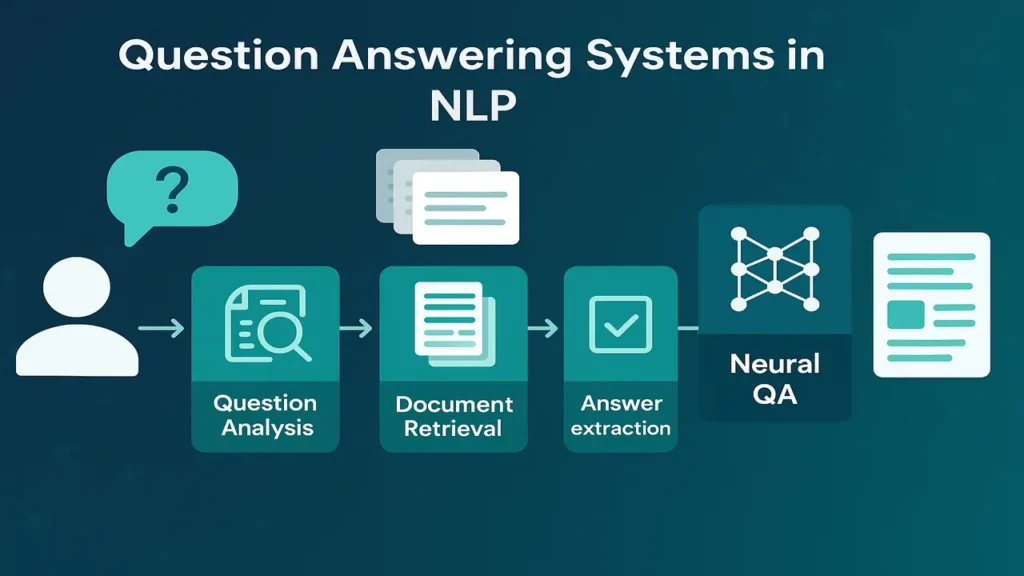
How question answering systems work, from information retrieval based pipelines to modern neural approaches in Natural Language Processing.
Question answering systems aim to respond to natural language questions with precise answers rather than long lists of documents. Instead of simply returning search results, a QA system tries to directly answer queries like “Who discovered penicillin”, “Which city is the capital of Japan” or “List the programming languages created by Guido van Rossum”.
This lecture introduces the main types of QA tasks, distinguishes between classical information retrieval based systems and modern neural QA, and presents the standard pipeline of question analysis, document retrieval and answer extraction. We also sketch how a simple QA system can be built over a small Wikipedia subset using techniques from earlier lectures on information retrieval and information extraction.
Lecture 11 – Information Retrieval, Vector Space Model and Evaluation
Types of question answering tasks
In practice there are several QA task families. It is important to understand their different requirements.
Factoid QA
Factoid questions expect a short factual answer, often a single entity or phrase. For example.
. “Who wrote Hamlet” → “William Shakespeare”.
. “When was the iPhone first released” → “two thousand seven”.
List QA
List questions require multiple items rather than a single fact.
. “Which countries are members of SAARC”
. “Name the operating systems developed by Microsoft”
A list QA system must detect that multiple answers are needed and aggregate them appropriately.
Open domain QA
Open domain questions can be about almost any topic. They usually assume access to a very large corpus such as all of Wikipedia or the web. Retrieval becomes a crucial component because the system must first locate relevant passages before extracting an answer.
Reading comprehension QA
In reading comprehension, the system is given both the question and one or more passages that are guaranteed to contain the answer. The task is to mark the answer span within the passage. Many benchmark datasets such as SQuAD follow this format. These tasks focus less on retrieval and more on understanding and reasoning over the given text.
These categories overlap in real systems, but they provide a useful framework when designing a course or system architecture.
Question answering versus search and information extraction
Question answering sits at the intersection of information retrieval and information extraction.
. From information retrieval (Lecture eleven) we borrow techniques for indexing large corpora, representing queries and retrieving relevant documents.
. From information extraction (Lecture twelve) we use named entity recognition and relation extraction to identify candidate answer spans and entities inside those documents.
A plain search engine returns a ranked list of documents. It is up to the user to read them and find the answer. A QA system attempts to go one step further by automatically selecting the exact phrase or entity that answers the question.
For example, if the question is “Where is the Eiffel Tower located” and a retrieved sentence is “The Eiffel Tower is a wrought iron tower located in Paris France”, a QA system should label “Paris France” or at least “Paris” as the answer.
Information retrieval based QA pipeline
Classical QA systems use a pipeline architecture with three main stages.
Step one. Question analysis
The system first analyses the input question. Typical operations include.
. Tokenisation and normalisation.
. Part of speech tagging and dependency parsing.
. Named entity recognition to detect entities mentioned in the question.
. Question classification to determine the expected answer type, such as person, location, date, number or list.
Knowing the answer type helps later filtering. For example, if the question starts with “Who”, the system should prefer person entities in candidate passages.
Step two. Document or passage retrieval
Next, the question is converted into a search query and sent to an information retrieval module. This can be a vector space model with TF IDF and cosine similarity as studied in Lecture eleven.
The retrieval module returns a ranked set of documents or passages likely to contain the answer. Many systems use short passages, such as single sentences or paragraphs, to reduce noise and focus the extraction step.
Step three. Answer extraction
Finally, the system runs an answer extraction component over the top retrieved passages. This component may use.
. Named entity recognition to find entities of the expected type.
. Pattern rules or dependency paths that often express answers to certain question forms.
. Scoring functions that evaluate how well each candidate span fits the question context.
The system then selects the highest scoring span and returns it as the answer, perhaps with a supporting sentence or document reference.
This pipeline is modular and interpretable. Each stage can be improved independently. However, its performance is constrained by the quality of hand crafted patterns and heuristic scoring functions.
For a neural, transformer based view of QA, the CS224N lecture on question answering provides excellent slides and discussion.
Neural question answering. high level view
In recent years, neural QA has become very popular. Instead of manually designing answer extraction rules, neural models learn to map questions and passages to answer spans or even generate answers directly.
Two common settings are.
Reading comprehension style neural QA
Given a question and a passage that contains the answer, a neural model such as a transformer computes contextual embeddings for all tokens in the concatenated question passage pair. A prediction head then outputs start and end indices for the answer span within the passage.
This approach is used by many pre trained models fine tuned on reading comprehension datasets. It removes the need for handcrafted patterns and can capture complex contextual interactions.
Open domain neural QA
In open domain settings, there is no given passage. We must first retrieve candidate documents, then apply a neural reader to each candidate.
A common architecture is retrieve and read.
. A retriever (for example TF IDF, BM twenty five or dense retrieval based on embeddings) selects a set of passages from a large corpus.
. A neural reader processes each passage with the question and predicts answer spans, assigning confidence scores.
. The final answer is chosen by aggregating scores across retrieved passages.
More recent systems integrate retrieval and reading even more tightly, or use large language models that can both retrieve and generate answers when connected to external tools.
Example. simple QA over a small Wikipedia subset
High level design.
- Select a small domain such as famous scientists, world capitals or Nobel Prize winners. Collect a few dozen Wikipedia articles in this domain and store them as plain text.
- Preprocess the documents. sentence segmentation, tokenisation, normalisation and optional lemmatisation. Build an inverted index and TF IDF document vectors.
- Implement an IR step that takes a question as a query and returns the top k sentences or paragraphs based on cosine similarity.
- Apply named entity recognition to the retrieved passages to identify person, location, organisation and date entities.
- Based on the question form, filter candidate entities. For example.
. For “Who” questions, prefer person entities.
. For “Where” questions, prefer location entities.
. For “When” questions, prefer dates. - Rank candidates by combining IR score and a simple heuristic such as proximity between the candidate entity and the main content words of the question.
- Return the best candidate as the answer along with its containing sentence as evidence.
Even though this system is simple, it shows how earlier course components come together. IR locates relevant content. NER and basic patterns pick answer spans. The result is a working factoid QA system over a small collection.
Real examples of question answering systems
Web search engines often show direct answers above the list of links, such as population figures, dates and short definitions. These are generated by QA components on top of large indices.
- Virtual assistants like Siri, Alexa and Google Assistant answer spoken questions using QA backends linked to knowledge graphs and web content.
- Customer support chatbots answer product questions by retrieving and reading knowledge base articles instead of sending users to search pages.
- Educational platforms provide reading comprehension exercises where models highlight text spans that answer student questions about a passage.
- Internal enterprise QA systems allow employees to ask natural language questions over manuals, policy documents and technical specifications.
Step by step algorithm explanation. classic IR based QA
Here is a stepwise view of a simple factoid QA pipeline.
Step one. Receive a user question q in natural language.
Step two. Perform question analysis.
• Tokenise and normalise the question text.
• Apply POS tagging and dependency parsing.
• Recognise named entities present in the question.
• Classify the question into an answer type such as person, location, date or number.
Step three. Formulate a retrieval query from the content words of q, possibly expanding it with synonyms or related terms.
Step four. Use an information retrieval module with TF IDF vectors and cosine similarity to retrieve the top N sentences or paragraphs from the document collection.
Step five. For each retrieved passage, apply a named entity recognizer and collect candidate answer spans that match the expected answer type.
Step six. Score each candidate span based on.
• the retrieval score of its passage
• the similarity between local context around the span and the question
• simple lexical patterns that link questions and answers
Step seven. Select the highest scoring candidate as the predicted answer.
Step eight. Return the answer along with a supporting sentence and optionally a link to the original document.
Code example. mini QA with TF IDF retrieval
The following Python example demonstrates a toy QA system that retrieves sentences and picks a short answer string based on simple heuristics. It assumes you have a small list of documents or sentences.
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
import numpy as np
# Example knowledge base: small set of sentences
sentences = [
"The Eiffel Tower is located in Paris France.",
"Isaac Newton formulated the laws of motion and universal gravitation.",
"The capital city of Japan is Tokyo.",
"Albert Einstein was born in Ulm in 1879.",
]
vectorizer = TfidfVectorizer(stop_words="english")
tfidf_matrix = vectorizer.fit_transform(sentences)
def retrieve_sentences(question, top_k=2):
q_vec = vectorizer.transform([question])
scores = cosine_similarity(q_vec, tfidf_matrix)[0]
top_idx = np.argsort(scores)[::-1][:top_k]
return [(sentences[i], scores[i]) for i in top_idx]
def simple_factoid_qa(question):
candidates = retrieve_sentences(question, top_k=2)
# Very naive answer extraction:
# return the last named-like token (capitalised word) from best sentence
best_sentence, score = candidates[0]
tokens = best_sentence.split()
capitalised = [t.strip(" .") for t in tokens if t[0].isupper()]
answer = capitalised[-1] if capitalised else best_sentence
return answer, best_sentence
if __name__ == "__main__":
q = "What is the capital of Japan?"
ans, evidence = simple_factoid_qa(q)
print("Question:", q)
print("Answer:", ans)
print("Evidence:", evidence)This minimal system.
. builds a TF IDF index over a small set of sentences
. retrieves the best matching sentence for a question
. chooses a capitalized token as a crude proxy for a named entity
Summary
Question answering systems in NLP aim to deliver concise answers to user questions by combining retrieval, understanding and extraction. Classical IR based pipelines perform question analysis, document retrieval and answer extraction with explicit modules, while modern neural approaches learn to read and answer questions using powerful transformer models, often on top of the same retrieval infrastructure.
By building on previous lectures about information retrieval and information extraction, students can see QA as a natural integration of indexing, linguistic analysis and semantic interpretation. Whether we are answering questions from Wikipedia, enterprise manuals or web pages, the core ideas remain the same. identify what the user is asking, locate relevant information and extract or generate a precise answer.
Next Lecture 15 – Text Summarization. Extractive and Abstractive
People also ask:
Question answering in NLP is the task of taking a natural language question as input and producing a direct answer, often a short phrase or list, by searching and understanding text or structured knowledge sources. It goes beyond simple keyword search by attempting to pinpoint the exact information requested.
Traditional search engines primarily return links or documents that match a query. Question answering systems aim to return the answer itself, such as a date, name or short passage, often along with a supporting snippet. They typically combine information retrieval with deeper linguistic processing and sometimes neural models.
A classic QA pipeline performs question analysis to determine the answer type, uses information retrieval to fetch relevant documents or passages and then runs answer extraction to locate the specific phrase or entity that answers the question. Each stage can use NLP components such as POS tagging, parsing and named entity recognition.
IR based QA relies on explicit pipelines and hand designed heuristics for answer extraction. Neural QA uses machine learning models, often transformers, that learn to locate or generate answers from examples. In open domain settings, modern systems often combine both approaches, using IR to retrieve passages and neural models to read them.
Real world applications include web search answer boxes, digital assistants that respond to spoken questions, customer support chatbots that answer product questions, internal enterprise QA over manuals and policy documents and educational tools that provide answers based on textbooks or lecture notes.